Plurai Introduces IntelliAgent: An Open Source Multi-Agent Framework for Testing Complex AI Conversational Systems

Testing conversational AI systems powered by large-scale linguistic models (LLMs) presents an important challenge for artificial intelligence. These systems must handle dynamic interactions, incorporate domain-specific tools, and accommodate complex policy constraints—forces that traditional assessment methods struggle to assess. Existing benchmarks rely on small, hand-picked datasets with earnings metrics, failing to capture the dynamic interactions of policies, user interactions, and real-world variability. This gap limits the ability to identify vulnerabilities or develop agents for use in high-profile areas such as health care or finance, where reliability is negotiable.
Current assessment frameworks, such as τ-bench or ALMITAfocus on smaller domains such as customer support and using static, limited data sets. For example, the τ bench tests airline and retail chatbots but includes only 50–115 manual samples per domain. These benchmarks prioritize end-to-end success rates, ignoring granular details like policy violations or conversation consistency. Some tools, such as those testing retrieval-augmented generation (RAG) systems, do not have support for multi-curve interaction. Relying on human design limits extensibility and versatility, leaving conversational AI analysis incomplete and ineffective for real-world needs. To deal with these limitations, Plurai researchers have introduced IntelAgent, an open, multi-agent framework designed to automate the creation of diverse, policy-driven scenarios. Unlike previous methods, IntelliAgent combines graph-based policy modeling, synthetic event generation, and dynamic simulations to fully evaluate agents.
At its core, IntelliAgent uses a policy graph modeling the relationships and complexity of domain-specific rules. Nodes in this graph represent individual policies (eg, “returns must be processed within 5–7 days”), each assigned a complexity score. The edges between nodes indicate the probability that policies occur simultaneously in a conversation. For example, a policy about adjusting flight reservations may be linked to one about refund periods. The graph is constructed using LLM, which extracts policies from the system's knowledge, measures their complexity, and estimates the probability that they occur together. This property enables IntelAgent to generate transactional events as shown in Figure 4—user requests paired with active database instances—with a weighted random walk. Starting with the first policy with the same sample, the system traverses the graph, accumulating policies until the complexity value reaches a predefined threshold. This verification method ensures that events include a uniform distribution of complexities while maintaining a realistic policy combination.
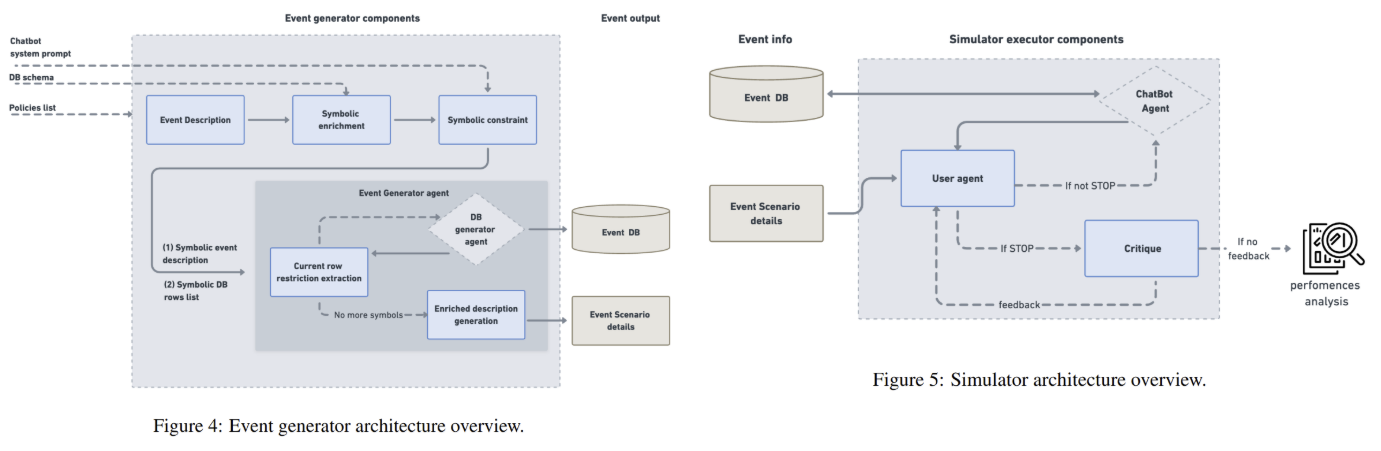
Once events are generated, IntelliAgent simulates conversations between a user agent and the chatbot under testa as shown in Figure 5. The user agent initiates requests based on event information and monitors the chatbot's adherence to policies. If the chatbot breaks the rules or completes the task, the connection is terminated. A part of criticism then analyzes the dialogue, identifying which policies were tested and violated. For example, in the case of an airline, criticism may flag failure to verify the user's identity before processing a reservation. This step produces well-analysed diagnostics, which reveal not only overall performance but specific weaknesses, such as struggles with user consent policies—a category neglected by τ-bench.
To validate IntelAgent, researchers compared its performance benchmarks against τ-benchmarks using state-of-the-art LLMs such as GPT-4o, Claude-3.5, and Gemini-1.5. Despite relying entirely on automatic data generation, IntelAgent achieved a Pearson correlation of 0.98 (airline) and 0.92 (commercial) with manually selected τ-bench results. More importantly, it revealed flawed data: all models failed user consent policies, and performance declined predictably as complexity increased, although the patterns of degradation differed between models. For example, the Gemini-1.5-pro outperformed the GPT-4o-mini at lower difficulty levels but met it at higher levels. These findings highlight IntelAgent's ability to guide model selection based on specific performance requirements. The modular design of the framework allows for seamless integration of new domains, policies, and tools, supported by open source implementations built into the LangGraph library.
In conclusion, IntelAgent addresses a critical bottleneck in the development of conversational AI by replacing static, limited testing with dynamic, scalable diagnostics. Its policy graph and automatic event generation enable comprehensive testing across a variety of scenarios, while well-analysed critiques point to potential improvements. By correlating closely with existing benchmarks and exposing previously unseen weaknesses, the framework bridges the gap between research and real-world deployment. Future enhancements, such as incorporating real-time user interaction to refine policy graphs, may improve its usability, solidifying IntelliAgent as a foundational tool for developing reliable, policy-aware conversational agents.
Check out Paper and GitHub page. All credit for this study goes to the researchers of this project. Also, don't forget to follow us Twitter and join our Telephone station again LinkedIn Grup. Don't forget to join our 70k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio extends with vision models, new language models, embeddings and LoRA (Promoted)
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS at the Indian Institute of Technology (IIT), Kanpur. He is a machine learning enthusiast. He is interested in research and recent developments in Deep Learning, Computer Vision, and related fields.
📄 Meet 'Height': The only standalone project management tool (Sponsored)



