Apple Researchers Introduce Instructive Pruning (IFPruning): An AI-Powered Approach to Developing Successful LLM
: An AI-Powered Approach to Developing Successful LLM")
Large-scale linguistic models (LLMs) have become important tools for applications in natural language processing, computational statistics, and programming. Such models often require large computing resources to make inferences and train the model efficiently. To mitigate this, many researchers have devised ways to improve the techniques used with these models.
A strong challenge to the effectiveness of LLM is that traditional methods of pruning have been modified. Static Pruning removes unnecessary parameters based on specified masks. They cannot be used if the required skill for the application is writing code or solving math problems. These methods are not flexible, as performance is often not taken care of for several tasks while developing computational resources.
Historically, techniques such as static structured pruning and mix-of-experts (MoE) architectures have been used to combat computational inefficiencies in LLMs. Structured Pruning removes parts such as channels or attention heads from certain parts. Although these methods are easy to use, they require extensive retraining to avoid loss of model accuracy. MoE models, on the other hand, activate model components during inference but incur large overheads from frequent parameter reloading.
Apple AI and UC Santa Barbara researchers have introduced a new method called Instruction-Following Pruning (IFPruning), which dynamically adapts LLMs to the needs of a specific task. IFPruning uses a sparsity predictor that generates a pruning mask that depends on the input, selecting only the most relevant parameters for a given task. Unlike traditional methods, this adaptive method focuses on the layers of a feed-forward neural network (FFN), which allows the model to adapt to a variety of tasks while reducing computational requirements efficiently.
The researchers propose a two-stage training process for IFPruning: First, proceed with the pre-training of dense models on big data, increasing the sparsity predictor and LLM. This produces a strong starting point for subsequent fine tuning. In the second stage, training is performed only on the fine-tuning datasets, using very different information for many tasks and examples. Masking is still powerful thanks to the online generation of sparsity predictors that cut unnecessary weights without affecting the performance of the models. This eliminates the need to reload the parameter, a limitation seen in earlier dynamic methods.
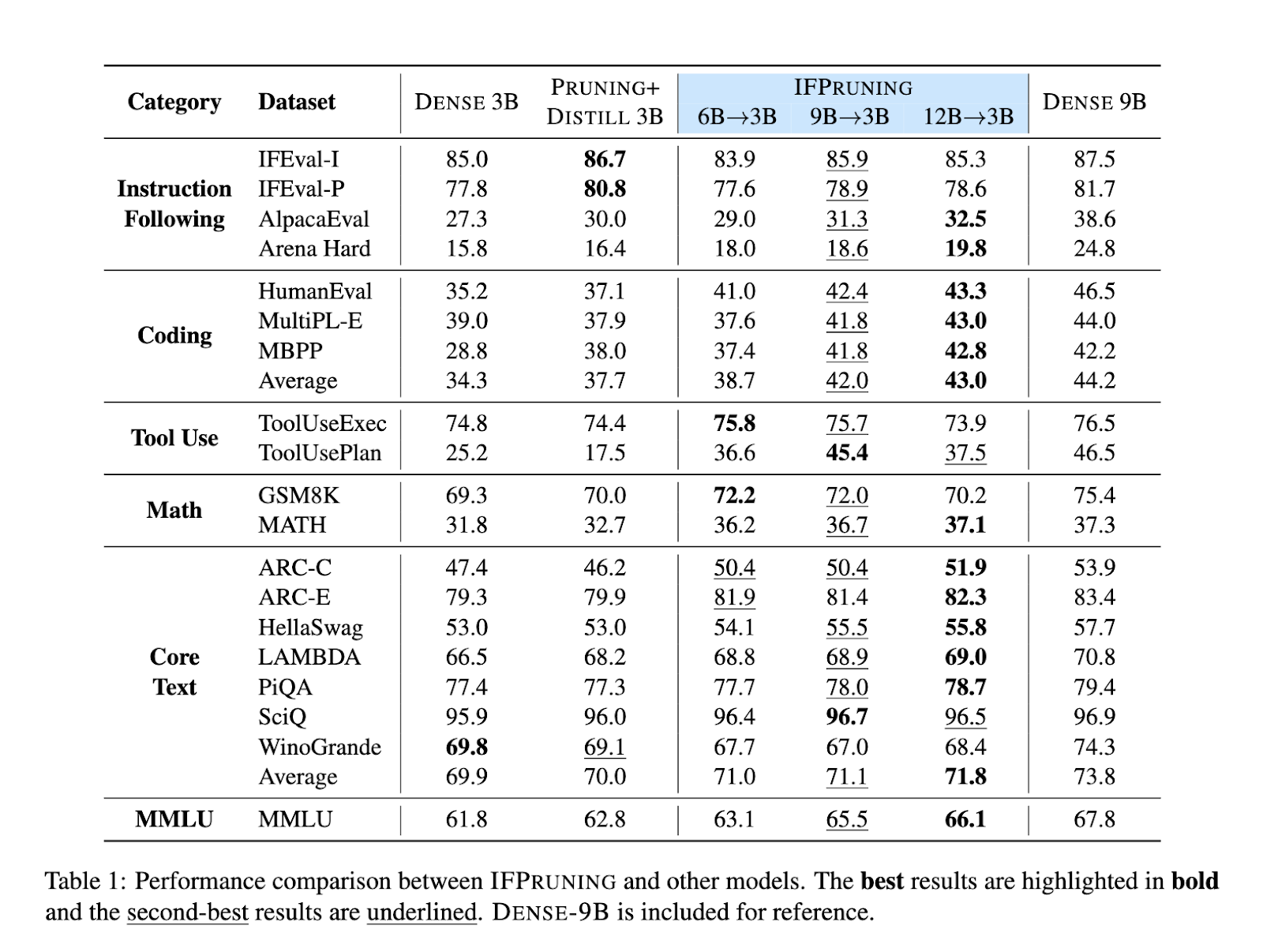
IFPruning's performance was rigorously analyzed across multiple benchmarks. For example, pruning the 9B parameter model to 3B improved the accuracy of the coding task by 8% compared to the dense 3B model, which is very close to the unpruned 9B model. For statistical datasets such as GSM8K and MATH, the dynamic pruning method yielded a 5% increase in accuracy. It has shown consistent gains in tests following instructions in both IFEval and AlpacaEval of about 4-6 percent. Even multitasking benchmarks such as MMLU, have shown promising results for IFPruning, showing flexibility in other domains.
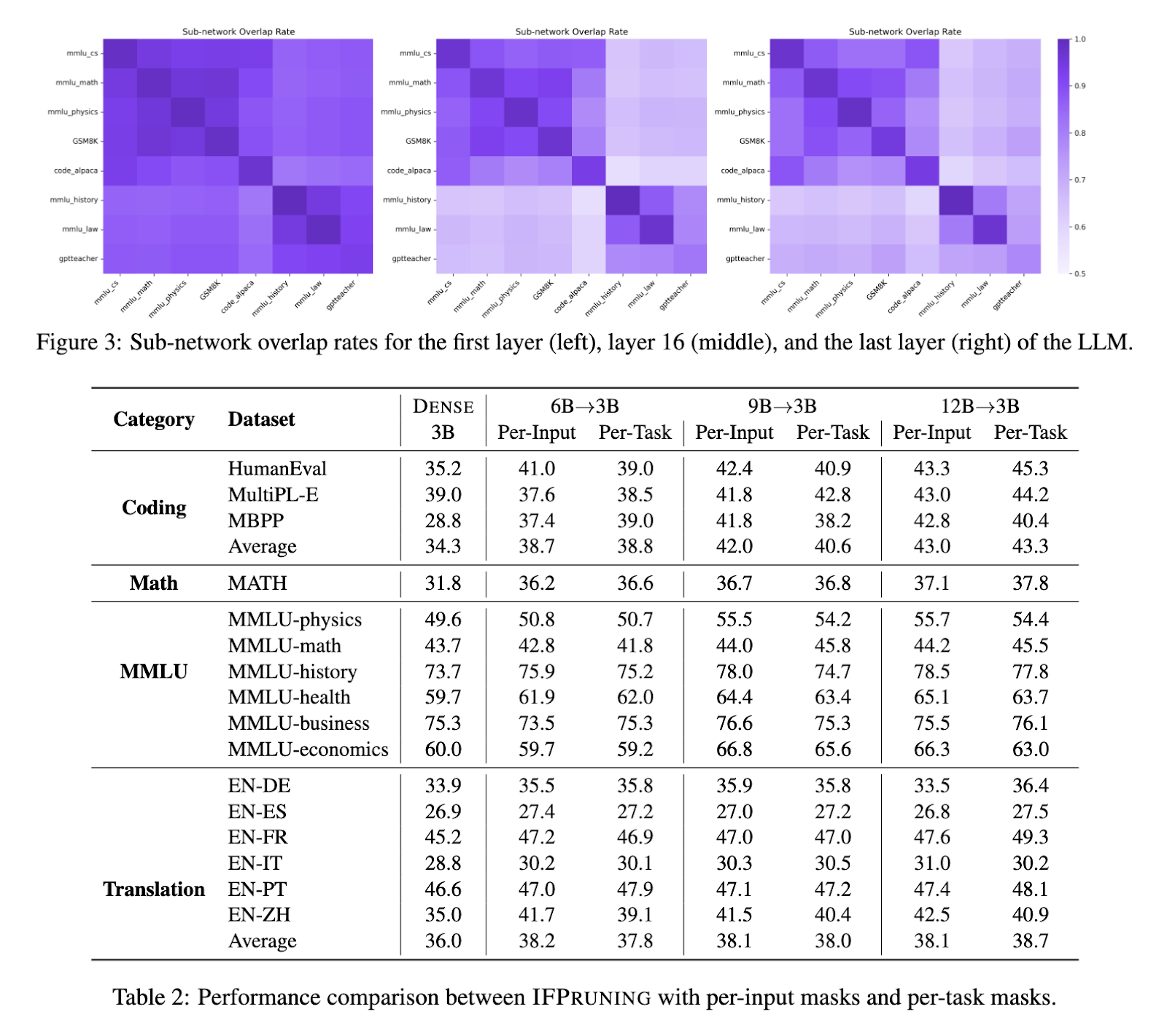
These results support the IFPruning approach's scalability as models with different sizes, namely 6B, 9B, and 12B parameters, were tested; in all, significant performance improvements after castration are found. Scaling from the dense 6B model to the dense 12B model showed that, under the same condition, the efficiency was improved as well as the task-specific accuracy. It was also more efficient than traditional systematic pruning methods such as Pruning + Distill due to the use of dynamic sparsity mechanism.
The launch of IFPruning marks a significant advance in developing LLMs, providing a method that dynamically measures efficiency and effectiveness. This approach addresses the limitations of static pruning and MoE architectures, setting a new standard for resource efficient language models. With its ability to adapt to various inputs without sacrificing accuracy, IFPruning presents a promising solution for the deployment of LLMs in resource-constrained devices.
This research will reveal further improvements in model pruning, including optimization of other components, such as attention heads and hidden layers. Although the methodology presented today addresses many computational challenges, further research into server-side applications and multitasking Pruning can increase the scope of performance. As a flexible and efficient framework, IFPruning opens up possibilities for flexible and accessible language types.
Check it out Paper. All credit for this study goes to the researchers of this project. Also, don't forget to follow us Twitter and join our Telephone station again LinkedIn Grup. Don't forget to join our 65k+ ML SubReddit.
🚨 UPCOMING FREE AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Data and Experimental Intelligence–Join this webinar for actionable insights into improving LLM model performance and accuracy while protecting data privacy.
Nikhil is an intern consultant at Marktechpost. He is pursuing a dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is constantly researching applications in fields such as biomaterials and biomedical sciences. With a strong background in Material Science, he explores new developments and creates opportunities to contribute.
📄 Meet 'Height': The only standalone project management tool (Sponsored)



