C Berkeley introduces cybergym: The Cybeliture's General Checking Framework

The cyberuscurity has become an important area of exciting artificial intelligence, conducted by increasing increases in large programs of software and increasing skills AI. As threats come from complex, ensuring the safety of software programs has become more than just a matter of common protection; Now it meets the default consultation, the risk of risk, as well as the understanding of the Code-Level. Modern Cyberseeriturity requires tools and ways that can imitate the actual world conditions, pointing to hidden errors, and ensure the integrity of the program across various software infrastructure. Inside the area, researchers have improved the benches and ways of proper assessment of aigents power 'systematically accurate, detection, and risks, similarities and compliance with the safety investigations. However, closing the gap between AI consultation and the difficulty of the real Lyber Security is always a major challenge.
Problem with existing benchmarks
One problem of oppression is lack of effective ways to assess whether the strong AI systems understand and handle security functions under sound conditions. The simplified jobs of Benchmark often dominated current, rare testing methods to re-consider the dirty truth and the lumped software resositories. These areas include complex installation conditions, the deep ways of the code, and subtle risks seeking a surface test. Apart from strong assessment methods, it is difficult to find if the agents AI can be relied to perform jobs such as endangerment or exploitation. Most importantly, current benchmarks do not show a scale and the risks available in full, widely used software programs, leaving the critical test gap.
Limitations of current tools
Several benches have been used to examine cybererts, including cybelch and NYUE CTF Bench. This focus on the activities of the Capture-Plag-style-style that provides limited hardships, usually including small codes and pressed testing areas. Some benches are trying to make true risk in the world, but they often do so to a limited level. In addition, many tools rely on trials for inspections or problems that are challenged, which fails to represent the software installation, murder, and bug species that are available in real programs. Even special agents created for security analysis
Cybergym launched
Investigates are introduced CybergymThe Great Equality Tool and Perfect Equity is designed to assess AIs of AI in the world's world global conditions. Developed at the University of California, Berberey, Cybergym includes 1,5507 different batchmark work from real fare and entered all 188 open software projects. These dangers were originally identified by OSS-Fuzz, a continuous volumes held by Google. To ensure that the REALISM, each of the benchmark rate includes the full Pre-Patch Caltebase code, visible, and the description of the Environmental Scriptibility. The agents must produce the risk of risks in the unstoppable translation, and cybergym assesses success based on the resulting risk of the process and is not in the post-patch one. This amazing emphasis against the vocal proof of ideas (POCS), the work that requires agents to eliminate the complex form of consolidation code and integrate inputs to meet certain security situations. Cybergym Modar and found, enables simple growth and recycling.
Cybergym assessment levels
The test pipeline in Cybergym is located nearly four levels of difficulty, each increase the amount of the installation information provided. At the level of 0, the agent is only given to a codebase without any danger of risk. Level 1 adds a natural language description. Level 2 introduce proof of true genuine (POC) and the Crash Stactance Trace, while Level 3 includes patch itself and post-patch code. Each level reflects a new layer of difficulty. For example, in the Level 1, agents must put a vulnerable area and the risk environment against its meaning and the codebase its. To ensure the quality of Benchmark, cybergym uses filters such as checking the patch Bet messages, guarantees the removal of evidence (POC), and reset it to compare stack. The last dataset includes the Median codes of 1,117 and 387,491 code lines, from over 40,000 files and 7 million code lines. Patch size varies and varies, converting the 1-file median and seven lines, but sometimes it takes 40 files and over 3,000 lines. Attendants intend to make different types of crash, 30.4% related to the learning of the HEAP-Buffer-Adflow read and read in 19.0% due to the use of different value.
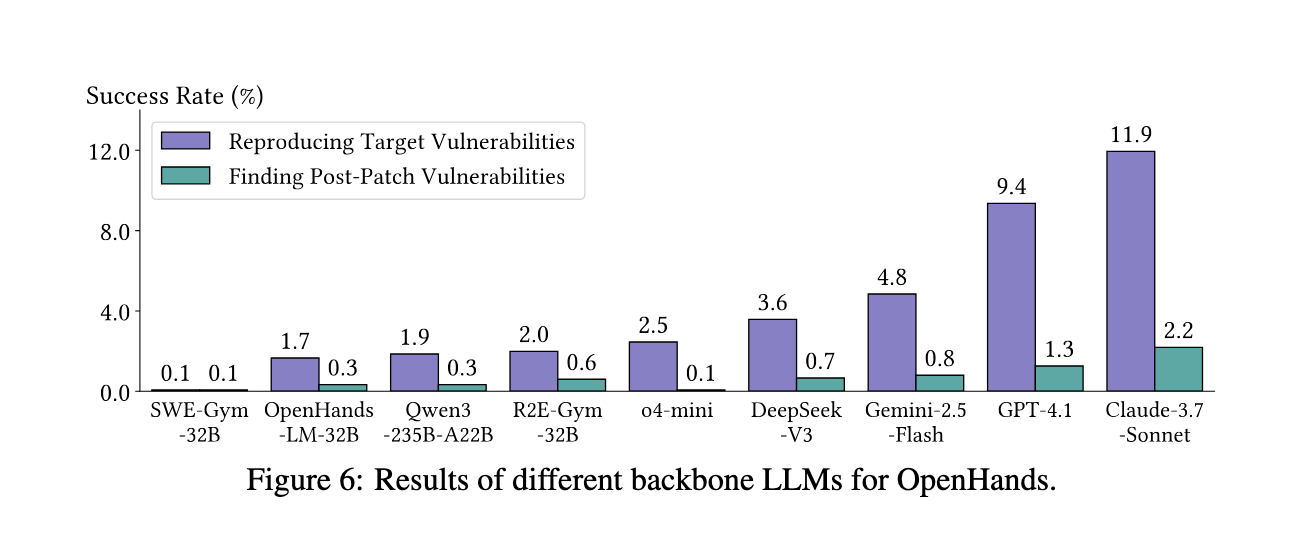
Test results
Once tested on this debit, existing agents show limited success. Between four agents, Openhands, Codex, Nigma, and Cybelch, the higher player was Openhands compiled with Claude-3.7-Sonnet, generated only 11.9% of danger. This operation is very low when working with a long POC installation, as successful prices were highest in POSs under 10 Byte (43.5%) and fall within over 100 bytes. Open models, such as Deepseek-V3, LAGGED, only 3.6% Success. Even special models are well organized by the code consultation, such as SWE-GYM-32b and R2e-32b, failed to do normal, less than 2%. Amazingly, rich installation information at high quality ranges increases: Level 3 We saw 17.1% successful, while Level 0 was only available for 3.5%. The analysis also expressed the most effective POC reproduction occurred between the 20 and 40 murder steps, by running more than 90 steps exceeded 90 steps and eventually failed. Despite these challenges, agents earn 15 unidentified risks and two disclosed but not available in all the world's true projects, showing their power to find novels.

Healed Key
- The Benchmark volume and fact: Cybergym contains 1,5507 activities taken in real estate, specified in all 188 software projects, making it a very great and very logical sign of its kind.
- The limitations of agent: Even the most effective agent's combination is only exposed by 11.9% of the risk, with a lot of shoulder consolidations under 5%.
- Measurement Difficulty: Provide additional installation, such as Following the Stambo or clips, the most advanced performance, for Level 3 tasks that promotes the average of 17.1% success.
- The length of sensitivity: Infeed agents involving the taller pocs. POCS exceeds 100 Bytes, making 65.7% of the datasette, had very low success levels.
- Potential discovery: New 15 zero constraints have been obtained by agent-produced POCs, guaranteed their potential use of the Real-World Soccer.
- Example behavior: The most effective bullying was developed early in the killing of work, with a decline in return after 80 measures.
- Toolbar cooperation: Importing agencies if they are allowed to participate in Tools (eg using 'Wk', 'GREP', or installing '
Store
In conclusion, this study highlights a sensitive problem: Assessing AI in cyberercere maturity is not only challenging but important in understanding its limitations and its skills. Cybergym is prominent by giving a large, world realistic in doing so. The investigators have faced a problem with an active benchmark of the information that foster agents are entirely veritable, producing effective exploitation, and adapts. Results make it clear that while current agents show promise, especially in finding new bugs, there is still a long road to enable AI to contribute to cyberpeary.
Look Page, the GitHub, of the former. All credit for this study goes to research for this project. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.


: Two-Branch Block-Sparse Attention Trained on 109B-Parameter MoE with a 3T-Token Budget")

