Thinking is difficult, not for a long time: To check well in advanced languages

Large models of language (llms) developed beyond the basic language process for dealing with problems with problems. While model size, data, and compute enabled the development of advanced internal suggestions and skills appear in large models, important challenges reside in their respective power. Current ways striving to maintain unity in all problems of solving, especially in the principles that require planned thinking. Difficulties exist in doing well to think about chain-of-temples and ensure consistent performance in various jobs, especially for challenging mathematical issues. Although the recent progress has been shown, researchers face the ongoing challenge of good use of computational resources to improve self-discipline skills. Improving systems that can formally improve solving problems while the preservation of the Scalability remains a major problem in llm's skills development.
Investigators have tested various methods of improving the consultation on the llMs. The deduction of the Study period investigates that models are inclined to steal or reduce, evaluate the step long, inserting, and standard failures. The past work focuses on building statistical thinking about clear–and-imagination during the learning phase and their analysis during approval. While these methods show improvements in the benches, questions still continue to function with the international power model and relationships between consultation and functional. These questions are important in understanding the way to compose the more effective systems.
This study uses Omni-Math Dataset on a thought bench that reflects different model variations. This data provides a difficult relief framework at the Olympics, addressing the restrictions of existing benchmarks such as GSM8K and statistics where the llms receive the highest price. Omni-Math Found Found into 33 domains in all 10 difficult levels enabling an understanding examination of mathematical skills. Omni-Juil access helps the default analysis of the answers produced in a prepared manner. While other benches, consultation, and GPQAs show different backgrounds, and Code benches highlight the importance of clear Reward models, Omni-Math's structure makes us very ready to analyze the relationship between the ability to consult.
This study assessed the functioning of model using OMNON-MATH Benchmark, which includes 4,428 problems Olympiad-Level Math six domestics and four heavy tigers. Results show clear stewards between the Models surveyed: GPT-4O has received 20-30% accuracy in several lines, is very full of models. O1-mini arrived at 40-60%; O3-mini (m) achieved at least 50% of all sections; and O3-mini (H) developed about 4% above O3-mini (m), more than 80% of Algebra and Calculus. The analysis of the Telekkela has revealed that the use of related token is increasing with difficulties of problems in all models, and dissatisfy statistics have great size. Important, O3-Mini (m) does not use more consultations than O1-mini to achieve high performance, raising effective thinking. Also, accuracy declines for all models, and the powerful effect of O1-mini (3.16% decrease in 1000 tokens) and reduce the O3-mini (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (H) (h). This shows that while O3-mini (h) is a better performance of lines, comes at high cost of computing.
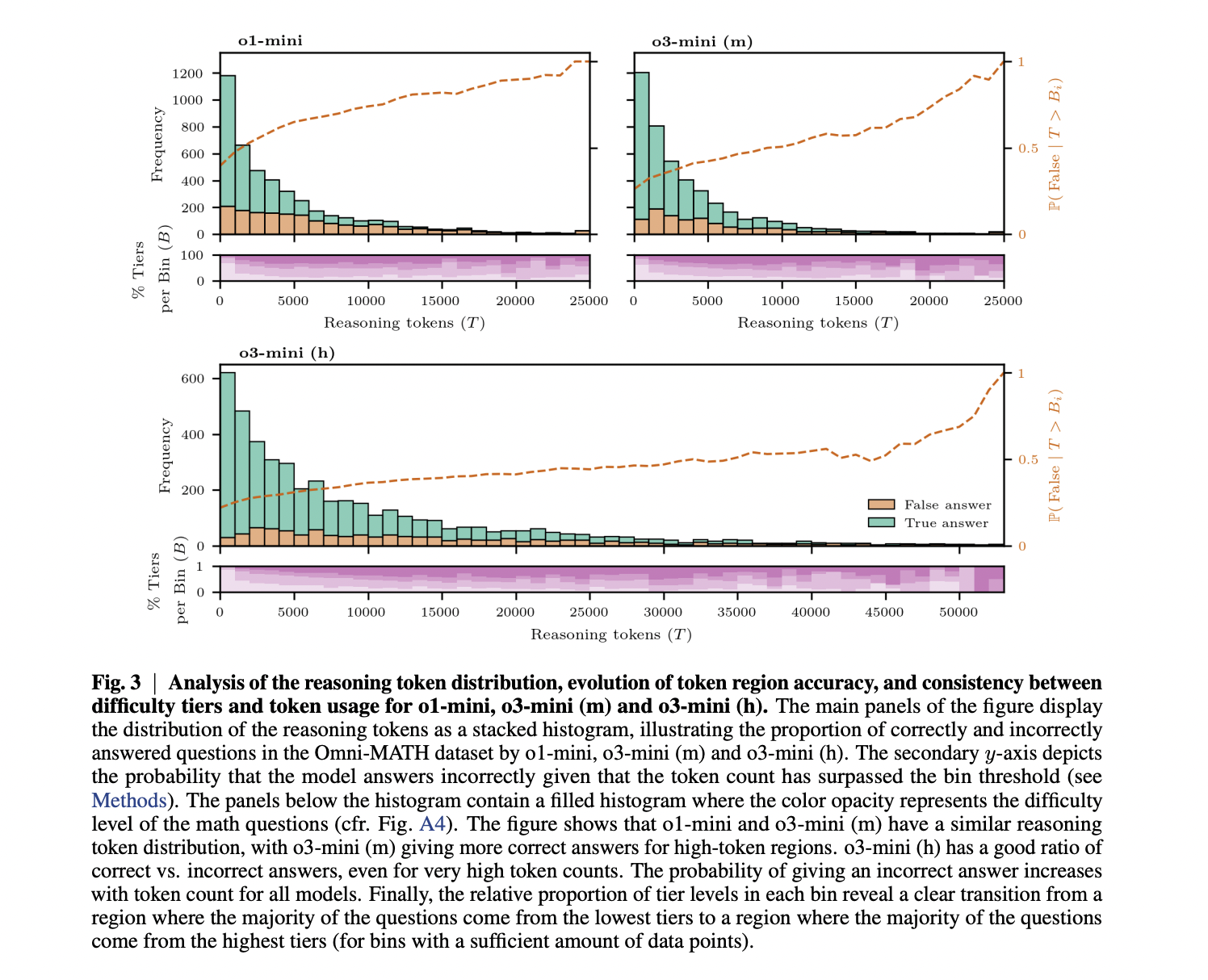
Studies show more findings about consulting language models. First, skilled models do not necessarily require long-term chains to achieve high accuracy, as shown in comparison between O1-mini and O3-mini (m). Second, while accuracy is decreasing in long-defining chains-of-tempty processes reduce advanced models, emphasizing that “hard thinking” is different “for long-minded thinking. This leadical decrease is possible because models are inclined to think of the problems they strive to solve to solve, or because showing opportunities that increase the power. Findings have practical effects of the model, suggesting that the stressful length is most beneficial to weak thinking models rather than tight, as it ultimately keeps reasonable accuracy even more reasoning. Future work can benefit from the metals of mathematical statistics to continue testing these dynamics.
Survey the paper. All credit for this study goes to research for this project. Also, feel free to follow it Sane and don't forget to join ours 80k + ml subreddit.
🚨 Recommended Recommended Research for Nexus
ASJAD is the study adviser in the MarktechPost region. It invites the B.Tech in Mesher Engineering to the Indian Institute of Technology, Kharagpur. ASJAD reading mechanism and deep readings of the learner who keeps doing research for machinery learning applications in health care.
🚨 Recommended Open-Source Ai Platform: 'Interstagent open source system with multiple sources to test the difficult AI' system (promoted)



