Liquid Ai's LFM2-VL-3B brings 3B Parameter Language Modeling (VLM) to class devices
 to class devices")
IICUM AI released LFM2-VL-3B, a 3B Parameter loy language model for image text to text functions. Transmits the LFM2-VL family over 450m and 1.6B range. The model aims for high accuracy while maintaining the speed profile of the LFM2 formulation. It is available for download and face-kissing under the LFM V1.0 open source license.
Model Overview and interface
The LFM2-VL-3B accepts composite image and text input and produces text output. The model exposed a chatml like template. The processor includes i
Expertise in housing construction
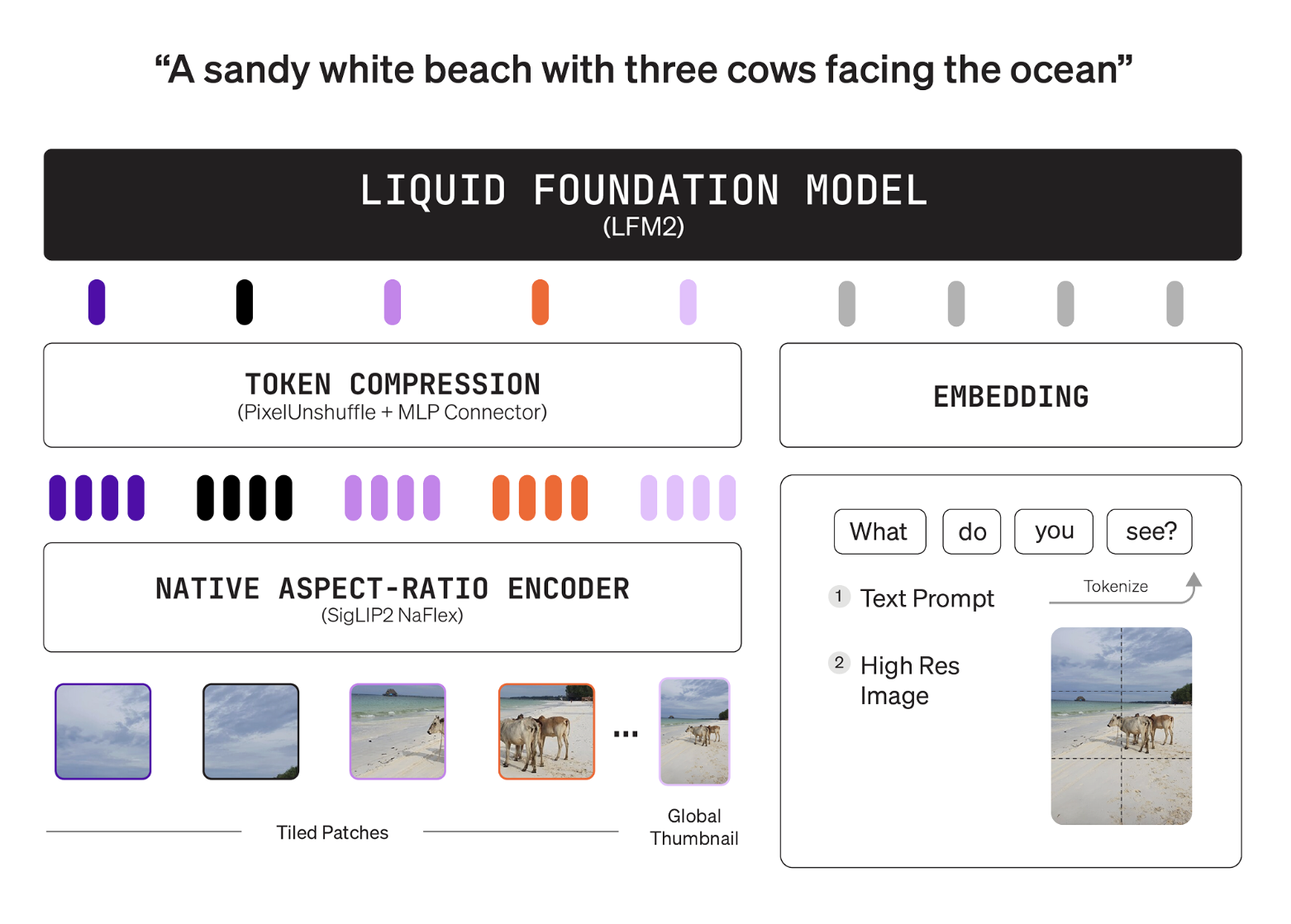
A stack of two is a tower of language in a familiar color with a projector's vision. The language tower is LFM2-2.6B, a Hybrid Plus Backbone solution. The Vision tower is Siglip2 Naflex in 400m parameters, it maintains the traditional traditional scale and avoids distortion. The linker is a 2 layer MLP with pixel uncuffle, it compresses the image tokens before combining with the language area. This design allows users of Cap Vision Token budgets without having to reinvent the model.
Encoder processes native resolutions up to 512 × 512. Larger inputs are divided into Notling 512 × 512 patches. The method icon method provides global context during editing. The working map of Phokhen is drawn with concrete examples, 256 × 384 image maps to 96 tokens, 1000 × 3000 image maps to 1,020 tokens. The model card presents the user controls with minimal graphic icons and a tiling switch. This controls the tune speed and quality during detection.
Measurement settings
The face hugging model card provides recommended parameters. The generation process uses temperatures 0.1, minutes p 0.15, and a multiplication penalty of 1.05. Vision settings use 64 min image tokens, Max 256 image tokens, and split image enabled. The processor uses the dialog template and the image messenger automatically. For example we use AutoModelForImageTextToText and AutoProcessor and bfloat16 accuracy.
How is it trained?
IICIM AI describes a systematic approach. This group performs intermediate training that converts text to image over time. The model was then carefully supervised by focusing on the understanding of the images. The data sources are large open data datasets and synthetic data for the House sonthetic work.
Benches
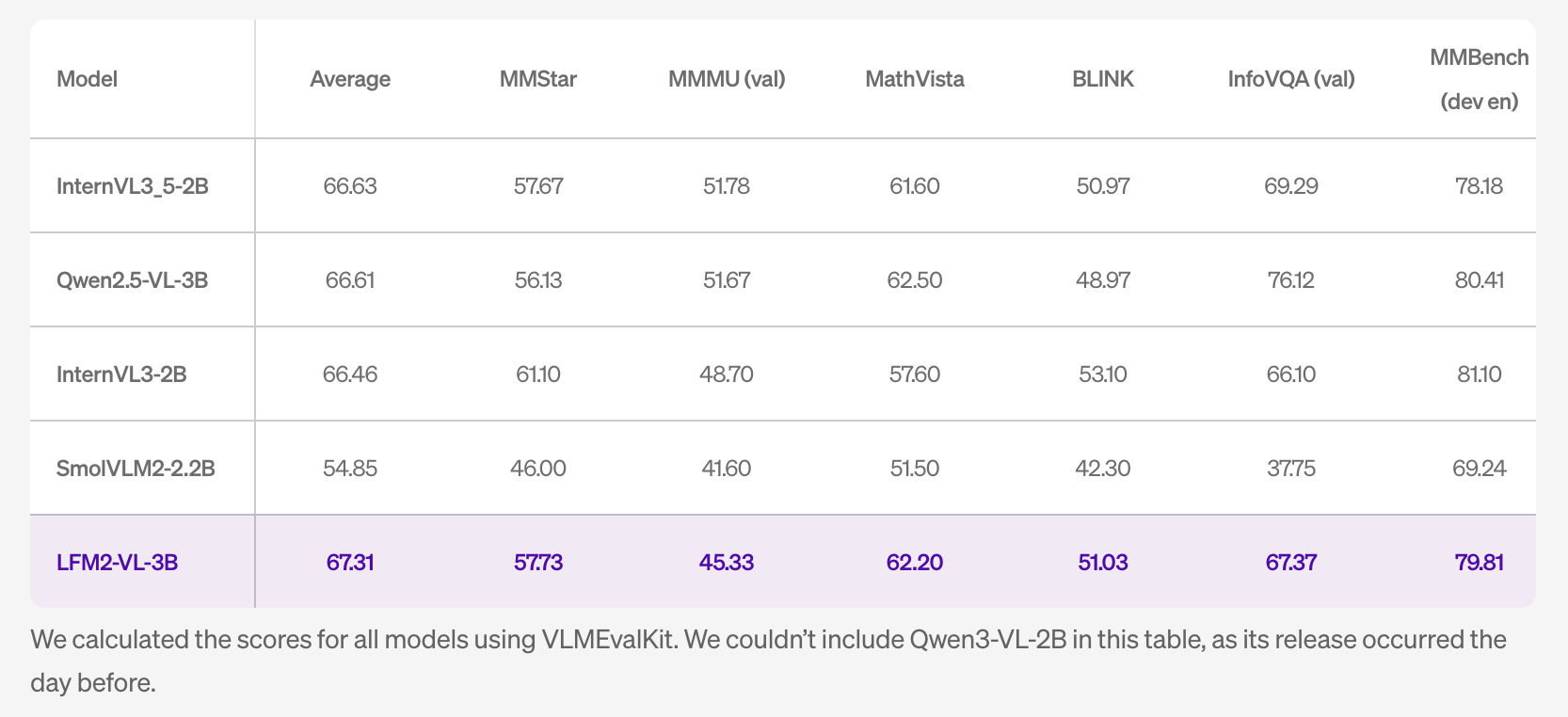
The research group reports the results of a competition between lightweight open VLMSs. In MM-Ifeval the Model reaches 51.83. In realworldQA it reaches 71.37. In MMBEMEND Dev En it reaches 79.81. Pope's score is 89.01. The table notes that scores from other programs were combined with VLMEVALLKIT. The table does not include Qwen3-VL-2B because that program was released one day earlier.
The power of languages remains close to the LFM2-2.6B Backbone. The research group scores 30 percent in GPQA and 63 percent in MMLU. This is important when cognitive tasks involve knowledge questions. This group also claims to increase the visual understanding of many languages beyond English, Japanese, French, Spanish, German, Italian, Portuguese, Arabic, Chinese, and Korean.
Why should end users care?
Architecture keeps compute and memory budgets small for the device. Image tokens are compressed and users are compressed, so the overload is visible. The Siglip2 400m NAFLEX Encoder maintains a good Aspect Ratio, which helps to understand what you are holding. The projector reduces the tokens of the connector, which advances the tokens per second. The research group also published GGUF Build on Device Times. These architectures are useful for robotic, mobile, and industrial customers who need local processing and tight data boundaries.
Key acquisition
- A compact multimodal stack: 3b Parameter LFM2-VL-3B in pairs LFM2-2.6B Mobe Ulimi with 400mm Siglip2 Naflex Encoder Encoder and 2-layer MLP projector for Image-Token Fusion. NAFLEX maintains the traditional traditional ratio.
- Management solutions and token budgets: Photos run Natural up to 512 × 512 input, large cosmetics then fit inside 512 × 512 clips with global Tumfnail Pathy. Written Token Mappings include 256 × 384 → 96 tokens and 1000 × 3000 → 1,020 tokens.
- The user interface: ChatML-like prompts with
- Performance measurement: Reported results include MM-IPEVAL 51.83, RealworldQA 71.37, MMBEZENT-DEV-NE-PAPE 89.01. LIMIT-ONLY signals from the back of the spine are approximately 30% GPQA and 63% MMLU, which is useful for complex modeling and information workloads.
The LFM2-VL-3B is an efficient step for multimodal workloads, the 3B stack pairs lfm2-2.6b with a 400m Siglip2 Naflex Encoder and a high-performance Map projector, which takes high image tokens for visual latency calculations. Traditional decision making with 512 by 512 cap tiling with wood gives the budget that we decide. Scores have been reported on MM-Ifeval, Realworldqa, Mbunch, and Pope are competing for this rating. Open instruments, gguf construction, and leap access reduce the combined tension. Overall, this is a VLM release optimized with clear controls and transparent benchmarks.
Look Model in HF and Technical details. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.

Michal Sutter is a data scientist with a Master of Science in Data Science from the University of PADOVA. With a strong foundation in statistical analysis, machine learning, and data engineering, Mikhali excels at turning complex data into actionable findings.
Follow Marktechpost: Add us as a favorite source on Google.



: enabling LLM agents to automatically discover smooth tools on any website")