Microsoft AI suggests bitnet distillation (bitdistill): A lightweight pipeline that delivers up to 10x memory savings and 2.65x CPU SpeedUp
: A lightweight pipeline that delivers up to 10x memory savings and 2.65x CPU SpeedUp")
Microsoft research is suggested Bitnet distillationThe most accurate LLMS conversion pipeline available 1.58 bit Bitnet readers for certain tasks, while maintaining accuracy close to the FP16 teacher and improving CPU efficiency. The method is inclusive Analysis of structures developed for the construction of Subln, Continues previous trainingagain Distillation of two signals from Logits and multiple attention relationships. The results of the results are reported Up to 10 × memory savings and About 2.65 × CPU fasterIt's metrically comparable to the FP16 in most sizes.
What does bitnet distillation change?
The community has already shown that Bitnet B1.58 it can match the perfect quality of accuracy when trained from scratch, but it modifies the FP16 model made directly from it 1.58 bit It usually loses accuracy, and the gap widens as the model size increases. Bitnet Distillation aims to transform this problem into effective Downstream deployment. Designed to maintain accuracy while delivering CPU friendly hardware with IT8 activations.
Phase 1: Model refinement with Subln
Small lower models suffer from large performance differences. The research team includes Subln normalization within each transformer block, in particular Before the release of the MHSA module and Before the release of the FFN release. This stabilizes the hidden scales of the state that flow in the measured projections, which improves the efficiency and conversion if the instruments are just heavy. Loss of training flows in the analysis phase supports this design.
Phase 2: Continue with pre-training to balance weight distribution
Understanding good work directly 1.58 bit It gives the reader only a small number of function tokens, it is not enough to look closely at the FP16 weight distribution of traditional constraints. Bitnet Distillation does a short ones continue the previous training In a typical Corpus, the research team uses 10B Tokens From the Falcon Corpus, pressing the instruments towards distribution. The visual observation shows a mass concentrated at the transition boundary, which causes small gradients to reduce the metals in between [-1, 0, 1] during staff training on the ground. This improves the ability to read without a full run of fun.
Stage 3: Distillation based on a good arrangement with two signs
A student learns from a FP16 teacher using Distillation transplantation and Multi Head Focusing Dispillation. The entry method uses soft temperatures between the distribution of teachers and Token students. The method of attention follows Minilm and minilmvv2 Composition, which conveys the relationship between q, k, v without requiring the same number of heads, and allows you to select a single layer to transform. The aberrations show that combining both signals works better, and that choosing a well-chosen layer is a good choice.
Understanding the consequences
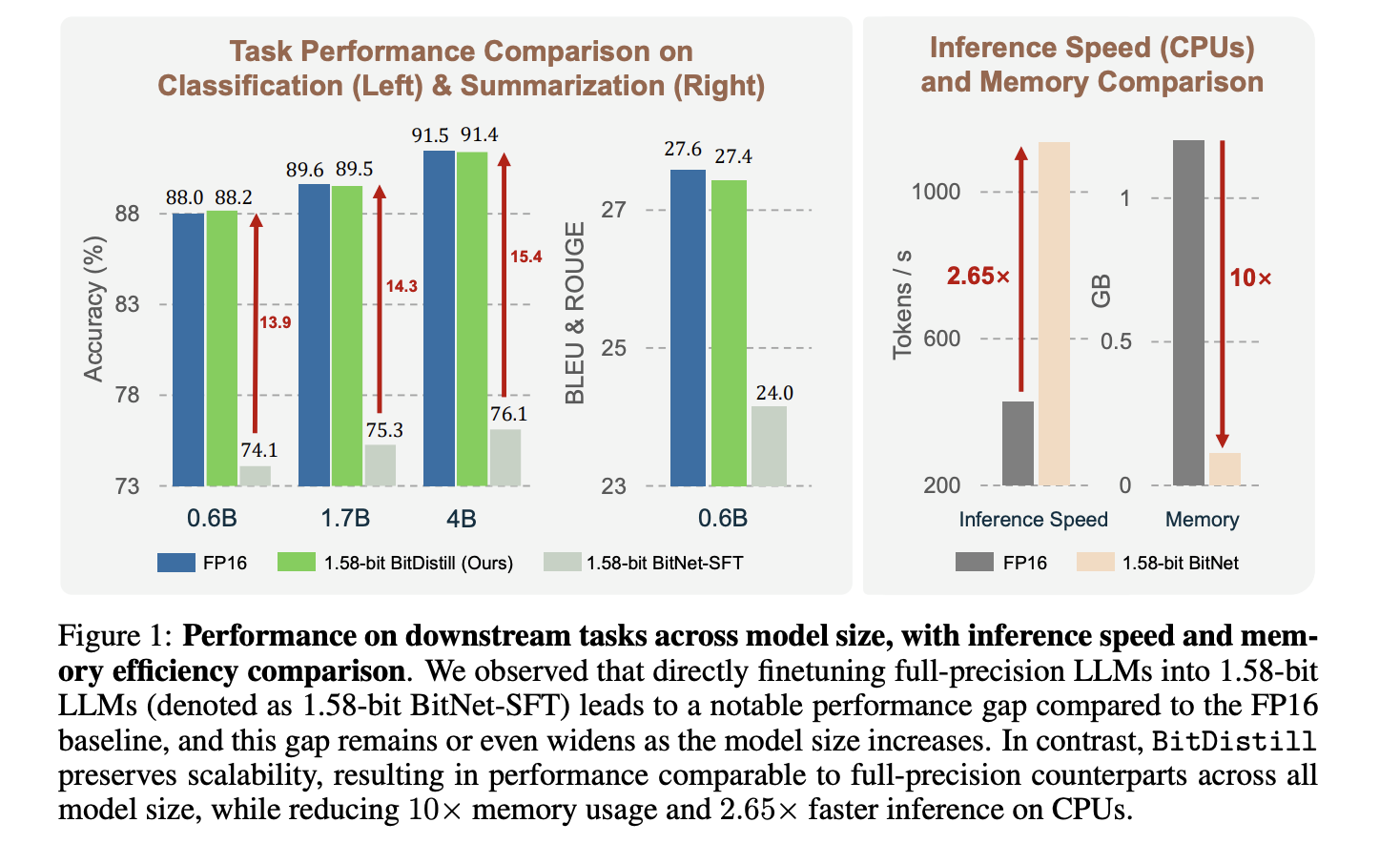
The research team examines classification, MNLI, QNLI, SST 2, and summarization on the CNN / Dailymail Dataset. It compares three settings, FP16 Task Good tunIng, direct 1.58 Bit Task PASHING HUND, and bitnet distillation. Figure 1 shows that bitnet distillation matches fp16 accuracy of Qwen3 backbones at 0.6b, 1.7b, 4Bwhile the 1.58 minimum vertical base increased significantly as the model size increased. For CPU, tokens per second Develop approx 2.65×and the memory is almost gone 10 × to the student. The Research Team speculates to work on Int8 and uses It's straightforward with measurement with a gradiimer degree.
The framework is compatible with structural learning methods such as The gptq and Pronounwhich provides additional benefits over the pipeline. The dynamic teacher decoration is very helpful, showing to combine small 1.58 bit students with large FP16 teachers when they are available.
Key acquisition
- Bitnet distillation is a 3-stage pipeline, Subln installation, continuation of previous training, and two removals from logs and multiple header relationships.
- Research reports close to FP16 accuracy with 10 × lower memory and about 2.65 × faster 1.58 bit readers.
- The method transfers attention using minilm and minilmvv style targets, which do not require the same head count.
- Checking the cover of MNLI, QNLI, SST 2, and CNN / Dailymail, and including QWEN3 Backbones in 0.6b, and 4B parameters.
- The deployment targets ternary hardware with IT8 activations, with optimized CPU and GPU kernels available from the official BitNet Repository.
Bitnet distillation is a pragmatic step towards the deployment of mini-reduction without full recovery, three-phase structure, subln, family attention pre-training, minilm family attention maps, known family alignment maps on a large scale. 10 Memory reduction Reliance on decorrelation testing is well removed from previous minilm work, which helps explain the robustness of the results. The presence of Bitnet.cpp with CPU and GPU kernels optimized at the risk of merging production teams.
Look Technical paper and Github repo. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of the intelligence media platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.
 for real-time implementation and integration of tools")
: A novel learning algorithm that trains a meta-weakness to design agentic workflows with dynamic llms")

