
Organizations often face challenges when implementing best-in-class methods optimized for their productive AI systems. The pure fine-tuning method involves selecting training data, preparing hyperparameters, and hoping for results that meet expectations without the power to make further changes. One good shot leads to suffutalTimal results and requires starting the whole process from the beginning when improvements are needed.
Amazon Bedrock now supports fine-tuning, allowing for systematic model refinement through controlled, incremental training cycles. With potential power you can create pre-set models, whether they are created in good order or installation, to provide a basis for further development without the risks associated with a complete restoration.
In this post, we'll explore how to use the power of Amazon Bedrock's fine tuning to systematically improve your AI models. We'll cover the key benefits over single-shot methods, walk through practical implementations using the console and SDK, discuss deployment options, and share the best options for maximizing your mockup results.
Using good iterative vicing
Iterative optimization provides several advantages over single-shot methods that make it essential in production environments. Risk mitigation is possible through incremental improvements, so you can test and validate changes before committing to larger changes. This way, you can make data-driven decisions based on actual performance feedback rather than theoretical assumptions about what might work. This method also helps developers to use different training methods in sequence to refine the behavioral model. Most importantly, the right architecture accommodates evolving business needs driven by continuous live data traffic. As user patterns change over time and use cases arise that are not present in the initial training, you can get this new data to refine the performance of your model without starting from scratch.
How to Use Order of Goodness on Amazon Bedrock
Setting up a good programming environment involves preparing your environment and creating training activities that build on your existing models, either through the console interface or through the SDK.
Requirements
Before you can start the beautiful design fun, you need a pre-made custom model as your starting point. This basic model can come from fine tuning or distillation processes and supports the desired models and variations available in Amazon Bedrock. You will also need:
- Standard IAM permissions for Amazon Bedrock Model customization
- Incremental training data focused on addressing specific performance gaps
- S3 bucket for training data and task results
Your incremental training data should look for specific areas where your current model needs improvement rather than trying to retrieve all the features.
You use the AWS Management Console
The Amazon Bedrock Console provides a straightforward interface for performing fine-tuning tasks.
Navigate to Custom models section and select Create a good job. The main difference in choosing a good plan is to choose a base model, where you choose your own pre-made model instead of the base model.
During training, you can visit the Custom models page in the Amazon Bedrock Console to track job status.
When you're done, you can check your performance metrics in the Console by using multiple metric charts, at Training metrics and Validation metrics tabs.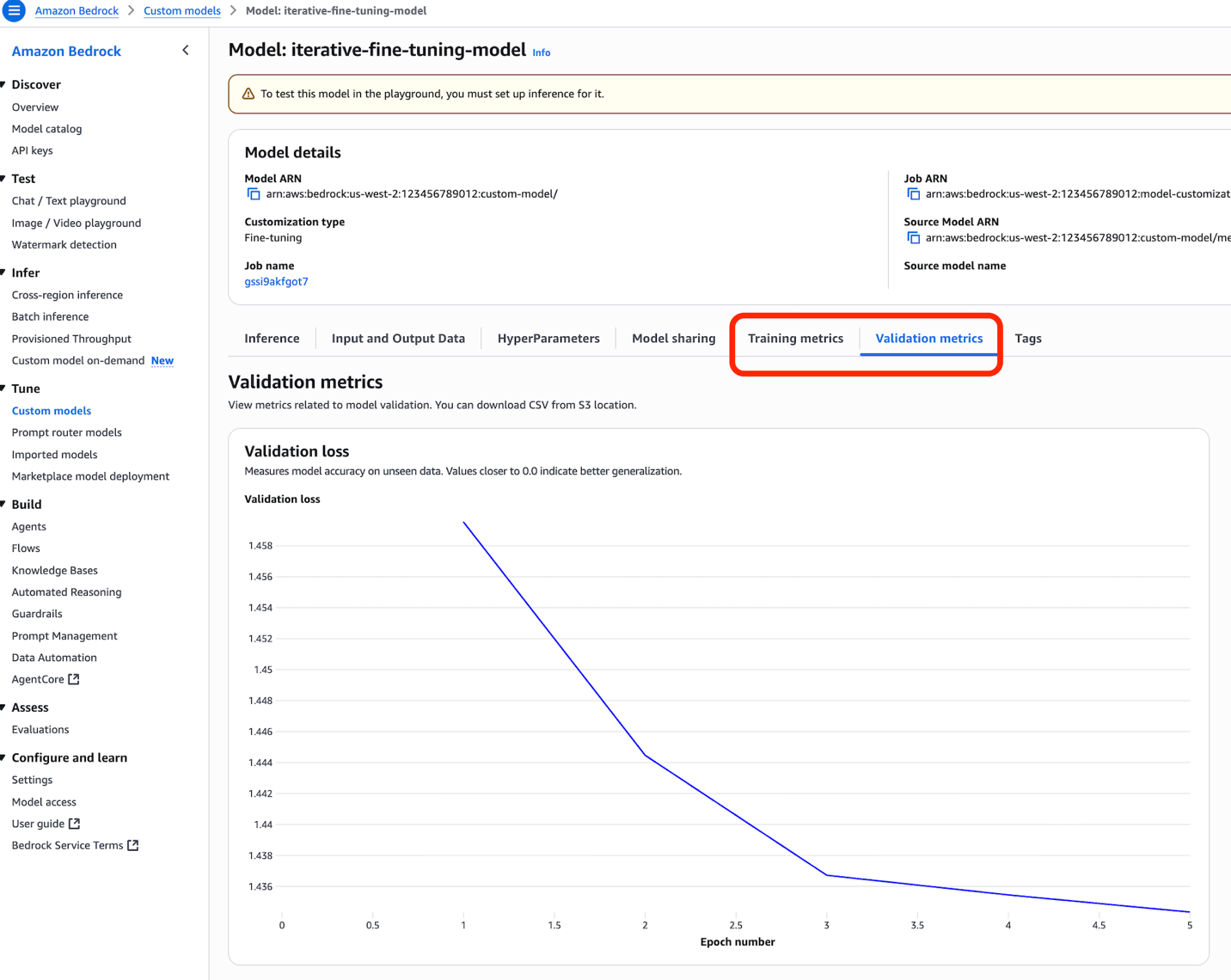
You are using the SDK
Programmac's implementation of Iterative Good-FineA follows the same patterns as regular fine-tuning with one critical difference: It specifies your previously generated model as a pointer to the base model. Here is the start of the example:
Setting up the humility of your well-prepared model
When your fine Finer-tuning job is complete, you have two main options for using your model to get your visualization, rendering and on-demand visualization, each suitable for different usage patterns and needs.
Filling provided
Provisioning that provides stable performance for virtual workloads where consistent usage requirements are met. This option provides dedicated capacity so that a properly configured model maintains performance levels during peak usage. Setup involves purchasing model units based on expected traffic patterns and performance requirements.
Discovery of demand
On-demand innovation provides flexibility for various tasks and test situations. Amazon Bedrock Now supports Amazon Nova Micro, Lite, and Pro models and LLama 3.3 models for Pay-Per-Toneken pricing. This option avoids the need to configure capabilities to test your well-configured model without an upfront commitment. The Pricing Model scales automatically with usage, making it useful for applications with unpredictable or low pricing patterns.
Best practices
A successful happy organization requires attention to several key areas. Most importantly, your data strategy should emphasize quality over quantity in the growing dataset. Instead of adding large volumes of new training examples, focus on high-quality data that addresses specific performance gaps identified in previous iterations.
To effectively track progress, informal consensus across ITerations allows for meaningful comparisons for meaningful improvements. Establish basic metrics during your initial phase and maintain the same evaluation framework throughout the process. You can use Amazon Bedrock testing to help you systematically identify where gaps exist in your prototype performance after each run. This consistency helps you understand that changes produce meaningful improvements.
Finally, knowing when to stop the process being used helps protect your investment. Monitor performance improvements between iterations and consider terminating the process when the benefits become marginal relative to the effort required.
Lasting
Good planning in Amazon Bedrock provides a systematic approach to prototype development that reduces risk while enabling continuous improvement. Good planning process organizations can build on existing investments in custom models rather than starting from scratch when adjustments are needed.
To get started with a good iterative vicolong, access the Amazon Bedrock Console and navigate to Custom models part. For more detailed instructions, see the Amazon Bedrock documentation.
About the writers
 Yanyan zhang He is a senior AI data scientist at Amazon Web Services at Amazon Web Services, where he has been working on AI / ML technologies at the edge as a killer AI expert, helping clients use generative AI to achieve desired results. Yanyan graduated from Texas A & M University with a PHD in electrical engineering. Outside of work, she loves to travel, work, and explore new things.
Yanyan zhang He is a senior AI data scientist at Amazon Web Services at Amazon Web Services, where he has been working on AI / ML technologies at the edge as a killer AI expert, helping clients use generative AI to achieve desired results. Yanyan graduated from Texas A & M University with a PHD in electrical engineering. Outside of work, she loves to travel, work, and explore new things.
 Gautam kumar Is an engineering manager at AWS AI Bedrock, leading custom efforts across all major infrastructure models. He specializes in coaching and good planning. An outdoor worker, he enjoys reading and traveling.
Gautam kumar Is an engineering manager at AWS AI Bedrock, leading custom efforts across all major infrastructure models. He specializes in coaching and good planning. An outdoor worker, he enjoys reading and traveling.
 Jesse Manti Senior product manager at Amazon Bedrock, an AWS DEENTION AI developer service. He works on the interaction of AI and human interaction with the aim of building and improving the AI products and services he produces to fulfill our needs. Previously, Jesse held team lead engineering at apple and lumeds, and was a senior scientist at a Silicon Valley startup. He has an MS and a PH.D. From the University of Florida, and an MBA from the University of California, Berkeley, business school.
Jesse Manti Senior product manager at Amazon Bedrock, an AWS DEENTION AI developer service. He works on the interaction of AI and human interaction with the aim of building and improving the AI products and services he produces to fulfill our needs. Previously, Jesse held team lead engineering at apple and lumeds, and was a senior scientist at a Silicon Valley startup. He has an MS and a PH.D. From the University of Florida, and an MBA from the University of California, Berkeley, business school.



