Liquid Ai issued LFM2-Audio-1.5B: EDIO Foundation model of END-TOD per SUB-100 MS RECTION LATENCY

Icum AI issued LFM2-Audio-1.5b, a model of the foundation of the compact audio and preparation of the text with one last stack. It puts itself due to low latency, real-time assistants on devices affected by resources, extends the LFM2 family in Audio while keeping small feet.
But what's new? A united spine that is a mess that is a confused I / o
LFM2-AUDIO transmits 1.2B-parameter LFM2 of the back language audio and text as the first sequence of the original. Especially, the model disentangles Sound representations: Installation is a continuously restricted installation from WaveForm Chankforms This avoids the consumption of artificial methods while storing the default training method.
On the start side, the extracted use of issued:
🚨 [Recommended Read] Vipe (Video Pose Pose): A Powerful and Powerful Tool of Video 3D video of AI
- Backbeone: LFM2 (Hybrid Loct + Attention), 1.2B params (LM ONLY)
- Audio Encoder: Fastconformer (~ 115m, Canary-180m-flash)
- Audio Decoder: RQ-Transforer is spraying down Me Codec tokens (8 codes)
- City: 32,768 tokens; Vocab: 65,536 (Text) / 2049 × 8 (Audio)
- Accuracy: Bloat16; License: LFM v1.0 open license; Languages: English
Two ways of generation of real-time service providers
- The United Nothing Generation For a live, speaking dialog when the model exchanges text and audio tokens to reduce visual latency.
- Subsequent generation For Asr / TTS (to change red-turned modelities).
Liquid Ai provides the Python package (liquid-audio) and gradio demo to produce this behavior.
Latency: <100 ms to the first audio
Liquid Ai Team reports latency latency finished below 100 ms From the second audio question to the first audio response – Reply representative found in effective use of use is faster than the models are 1.5 parameters under its setup.
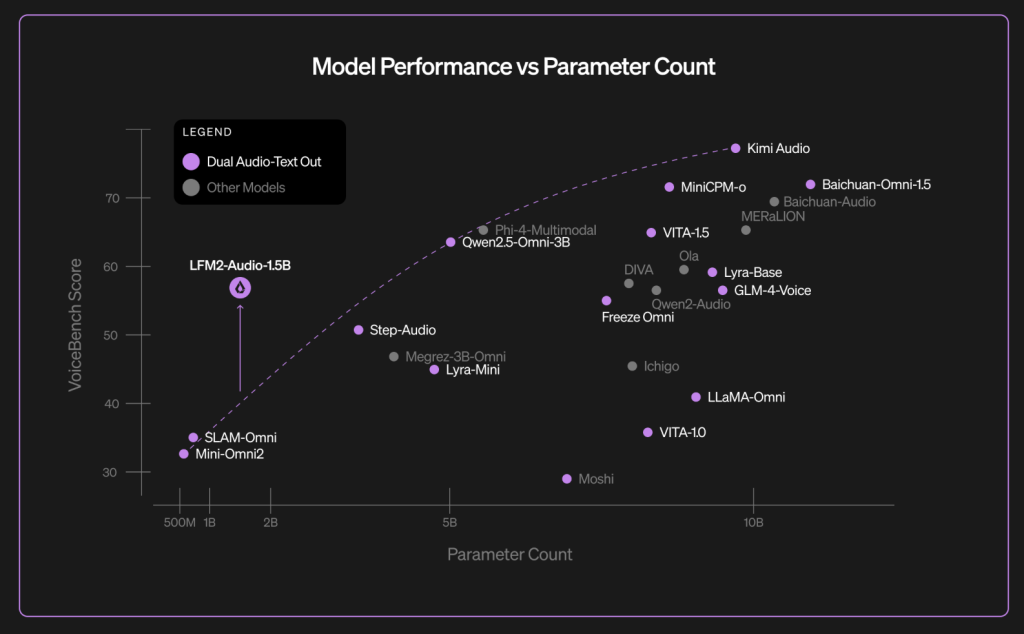
Benchmarks: Voicebelch results with Asr
Despite of- Fool-Ela Suite for the 8-fluid shohyology reports Scond Scond of 56.78 For the LFM2-Audio-1.5B, with the numbers of each work that are featured in the blog chart (eg Alpacaeval 3.71, General 3.49, Wildvoice 3.17). Liquid Ai group distinguishes the result in large models such as accusations. (Voicebeench is an external benchmark presented in late 2024 from llm-based voice supporters))
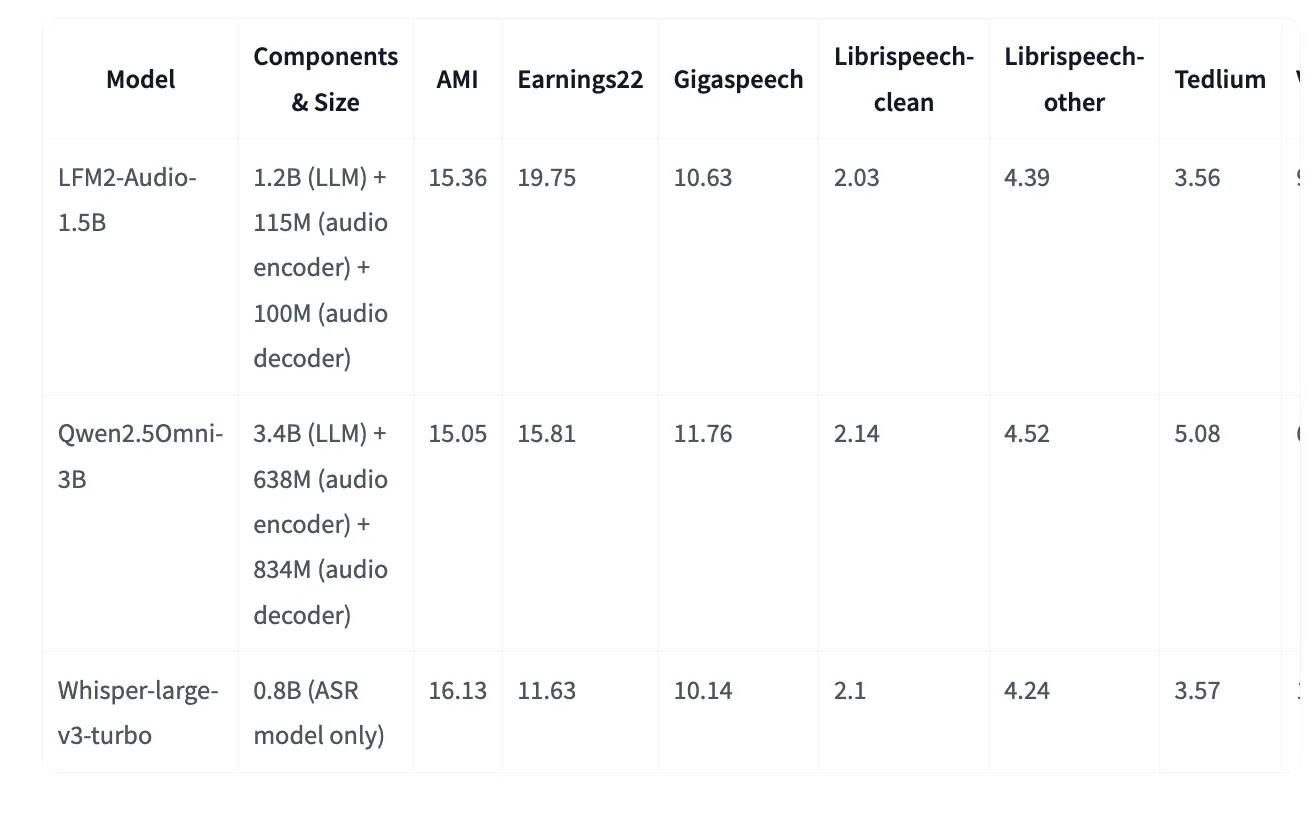
Model card in Joint Face Provides additional VoiceBench table (most relatively related – but not the same amounts) and including Classic Ass WFM2-Audio-Audio Matale or upgrade Shisper-Great-V3-Turbo to find more details although it is a common expression model. Example (lowly better): my 15.36 vs. 16.13 (Whisper-Large-v3-turbo), Librispecteech-Clean-2.03 vs 2.10.
Okay, but why does it really matter in Words Ai?
The Most “Omns” Stakimbim Couple Asr → LLM → TTS, add a latency and Brittle Meeting. Design for one LFM2-audio back with inserting codes and dissolve codes reduces the idea of glue and allows between the initial sound exit noise. For developers, this translation of the simple pipes and quick pipes, while supporting Asr, TTS, classification, and chat agents from one model. Liquid Ai provides Code, Demo entering points, and distributed by the face of the face.
Look GitHub page, Kissing one of the face model card including Technical Details. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper. Wait! Do you with a telegram? Now you can join us with a telegram.
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.
🔥[Recommended Read] NVIDIA AI Open-Spaces Vipe (Video Video Engine): A Powerful and Powerful Tool to Enter the 3D Reference for 3D for Spatial Ai

 The results described by GPUS, CPUS, and accelerators aeve")
 ekuvikeleni kwe-AI ruderative kanye nokuhlanganiswa okubomvu")
