Mimomi Dictiono Is Demo-Audio, a 7b Luther Language Trained 100m + Hours + for high-dependent tokens

Chiomomi's Combo group has issued MIMO-AUDIO, a seven-million-million-language model that uses one purpose of the next Token with a combined text and a toxic, aggressive and over 100 million audio.
What's new?
Instead of leaning on certain headaches or lost tokens, Mimo-Audio uses betpoke RVQ (Desidal Vectration) token intended Semantic reliability and high update. Tokenzer is working at 25 hz and 8 result of the 8ths of 8
Building: Patch Encoder → 7B llM → Capch DeCoder
Managing audio / text management of the LM use of LM (bottom of 25 hz victim of the Redbook Individual for Standartize Synthensis and respect to leaning. All three parts of Capk-patch Capker, Mimo-7B Backbe, and Captt Decoder-trained under one of the following purposes.
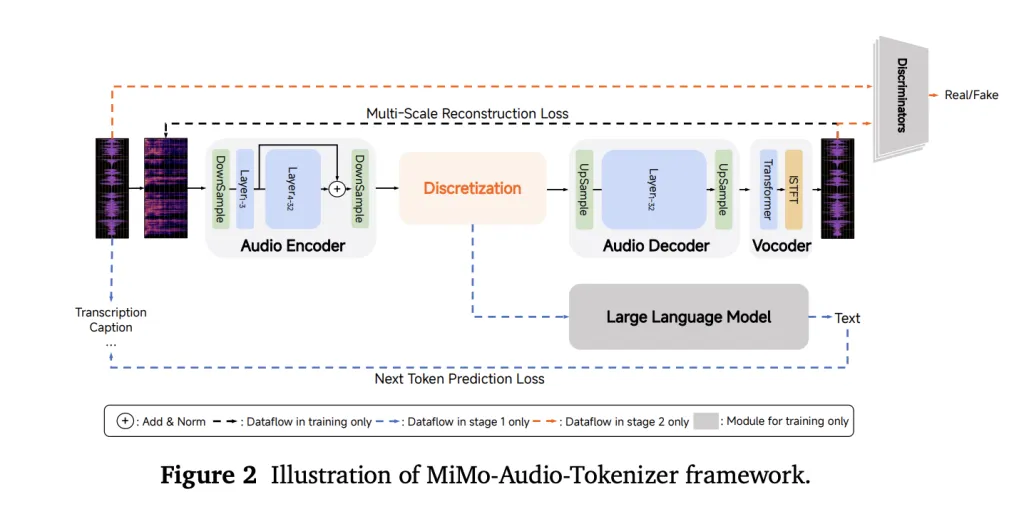
Scale is algorithm
Training continues in two major stages: (1) The “understanding” of the Interict Experty-Text Colle, and (2 in the Scripture-only.
Benchmarks: Talk of expression and general sound
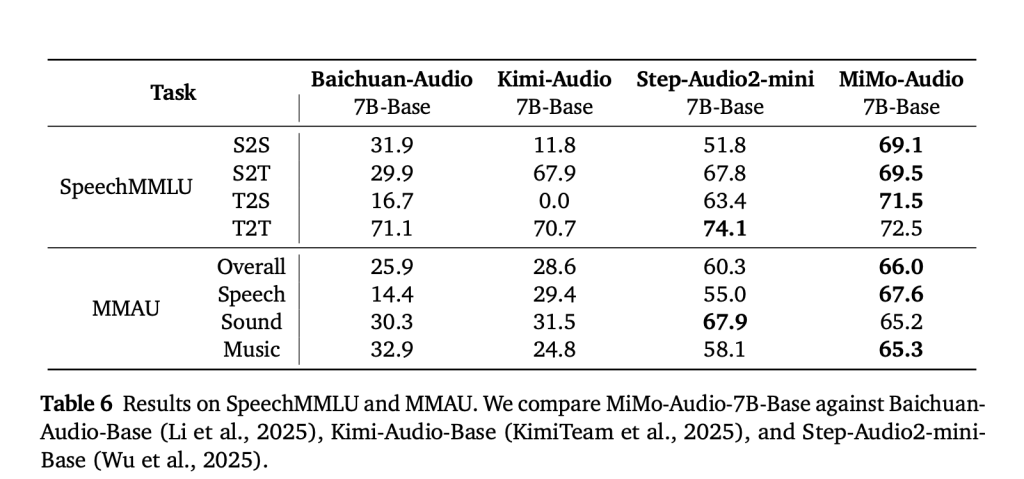
MIMO-AUDIO tested on suppressi-SPECTIENT SUMES (eg Speentmmrum) and unsuccessful benchmarks (eg mma. Xiaomi also released Mimo-Audio-AvalCommunity tool tool to reproduce these results. Demons of obedience and Answer (ongoing speech, transformation / emotions, mood conversion, and transformation talks) available online.
Why is this important?
The way is deliberate – no tower with many heads, no Bespoke Asr / TTS goals in the area of no more GPT-Token predicted lost Audio Plus tokens. Important engineering ideas (i) the Tokenzer LM can actually use the prosody and the formation of the speaker; . and (iii) the delay of the quality of the quality during the production. Kumaqembu ezakhiwayo ama-ejenti akhulunywayo, lezo Design Choices zihumusha ukuhlela okudutshulwa kokudubula inkulumo-kuya-enkulumweni kanye nokuqhubeka kwenkulumo okuqinile nokuhlawuliswa kwe-task-task-ekhethekile.
6 To take technology:
- High-Fidelity Hockey
Mimo-audio uses Convq Tokozer working at 25 hz with 8 actible coodibooks, to ensure that speaking tokens maintain prosody, timbre, and ownership of the platform while they end up friendly. - Pashiyed model Sequence
The model reduces the sequence of 4 Timestaps in one patch. - The next Hotel-Token objective
Instead of separating the heads of Asr, TTS, or Directorio, Audio Railway under the following predicted predicament in the joint venture, making buildings of many buildings while supporting a variety of work. - Outstanding Energy Avel
A few hard work as the continuation, transformation, emotions, emotions from if training exceeds larger data limit (~ 100 hours, tokens). - Benchmark leadership
Mimo-Audio sets State-of-The-Art Scores in Speetemmmlu (S2S 61.5) and Smya (66.0 Note), while reducing text information gap in 3.4 points. - The release of an open ecosystem
Xiaomi provides Tokenzer, 7b checkpoints (Basis and ordering tools), Mimo-Audio-evilo-evalt, and public Demos, give researchers to look at open speech.
Summary
Mimo-Audio shows that the highest Tokenzation, “RVQ-Based” “Non-Patched-Token Preteleng on a balcony is enough to open a few words without some heads. 7B Stack-Tokenzer → Capch Encoder → LLM decoder decoder-brodes Gap / 25 → 6.25 hz) by default, model decreases the text gap
Look Paper, technical information including GitHub page. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.

Michal Sutter is a Master of Science for Science in Data Science from the University of Padova. On the basis of a solid mathematical, machine-study, and data engineering, Excerels in transforming complex information from effective access.
🔥[Recommended Read] NVIDIA AI Open-Spaces Vipe (Video Video Engine): A Powerful and Powerful Tool to Enter the 3D Reference for 3D for Spatial Ai



