Microsoft issued by Vinivice-1.5B: Open-Sold Text-to-Spient Model Undoquent 20 minutes to talk about four different speakers

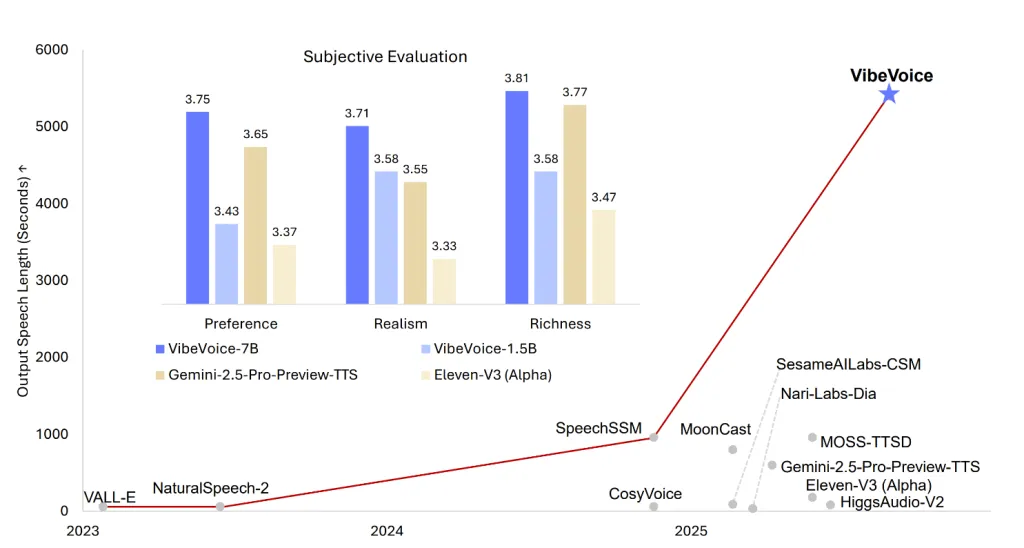
Release of a Microsoft open source, Vinivice-1.5BReferring to Text-to-Distmume Borders (TTS) – a long form, audio-speaker in a license, adhered to the use of research. This model is not just another TTS engine; It is designed to produce 90 minutes of interruption, environmentalism, vocational support and generation. According to the Broadcasts and Great 7B model announced the nearest future, Venetice-1.5B positions themselves as a major accessory Ai-POIDS audio, podcasting, and the research word.
Important features
- The main context and sponsor support: Vinivice-1.5B can match until 90 minutes of expression and in the reach of Four different speakers In one-time-passing away from the random platform of traditional TTS models.
- One generation: The model is not just packed together with the pieces of one word; designed to support Corresponding sound streams For many speakers, imitate the environmental conversation with taking the opportunity.
- Cross-crossing and singing synthesis: Whereas trained primarily in English and Chinese, the model is able to synthesis that fell It can also produce even singing-facts that are rarely shown in the most open source models of TTS.
- License: Perfect and commercial source, focus on research, hidden, and reproductive.
- Scale of broadcast and audio audio: Architecture is designed Quick Adversades for Long Time and waiting for the coming arrival 7B distribution – it knows The model, one and increases TTS opportunities for real time and High-Fidelity TTS.
- Feelings and showing: The model is found Emotional Control including DisclosureMaking ready for apps such as podcasts or chat conditions.
Architecture and Technical DEPE DIVE
Vineviice's Basis a 1.5B-Parameter llm (QWEN2.5-1.5B) that meets with two novel tokenzers-Acoustic including Potent-Obody designed to work a Less frame level (7.5hz) By the effitational and harmonious efficiency of another long order.
- Acoustic Tokozer: A σ-vae is different with a hierarchy-decoder structure (340m boundaries), benefits 3200x calms down from a green audio by 24khz.
- Semantic Tokozer: Astrus Proxy Task Training, this is the advice of the Encoder-Only Construction Construction Construction of Acoustic Design Tokozer (removes VAE components).
- Decoder Decoders head: Light parameter (~ 123m) Conducting terms of interruption module predicts acoustic characteristics, the direction of the classifier-free line
- The curriculum of cultivation: First training in the 4K tokens and scales until 65k tokens-The fun Model to produce long, audio components.
- Following the model: The llm understands the flow of the opportunity to take the opportunity, while the defacusion head produces good acoustic information for the information and separation while the synthesis while it is on the puppy of the speaker.
Model limit and reliable use
- English and Chinese only: The model is only training in these languages; Some languages can produce mysterious or offensive results.
- There is no more communication: While supporting taking the opportunity, Venice-1.5B makes Not a model of a talk Among the speakers.
- Talk: Model does not manufacture background sounds, foley, or musicReadio Output is a strong speech.
- Official and moral risk: Microsoft clearly prevent the use of By word, science, or testifying evidence. Users must comply with the laws and disclose the content that AI produced.
- Not with real time applications for real time: While effective, this is released Not prepared for low, valid latency, or live conditions; That is the 7b 7b target.
Store
Microsoft's Vinivice-1.5B Is open TTS success: SCALE, visible, and coordinating the supportive support of the most technical guidance, the alteration of the comprehension of investigators and open developers. While the use of the present Research – Focused It is also restricted in English / Chinese, skills of model – and promise of the coming translations – the AI change sign can create a way AI can produce and participate with the action.
For technical groups, content creators, and AI lovers, Vinivice-1.5B Is a tool that will test the next generation app for synthetic apps – available now in the face holders and GitTub, with clear documents and open documentation. As Field Pivots look at the most evolved, practical, and submissive of TTS, Microsoft offer is a symptom of the Open Sound Synthesis.
Kilombo
What makes Venice-1.5b different from other Text-to-Peatul models?
Vinivietice-1.5B can produce 90 minutes of audio audio, variety .
Which is recommended by hardware to activate local model?
Social examination indicates that it creates a variety of dialoog varied in the 2.5 B tests ≈ 7 GB of GPU VRAMTherefore the 8 GB consumer card (eg RTX 3060) is usually enough to be humble.
What languages and sound styles that support the model today?
Vinivice-1.5B only trained in English and Chinese and I do timing narrative (eg, immediately in English → Chinese talk) and the foundation Setting Planning. It produces only talk – no background sound – and does not include more speakers; Taking a chance in a row.
Look Technical report, The model in the kisses of face including Codes. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.



