NVIA AI issues Nemotron Nano 2 AI models: Family prepared for AI and 6x business production is faster than the same size model

Nvidia reveals the family of Nemotron Nano 2, introducing a hybrid Mbako-transformer's large models that have investigated accuracy but also offer up to 6 × 5 ×s of the matching matches. This release is implied without a disputing manner, as NVIDIA provides a majority of training corpus and recipes on the side of the public test model. Obviously, these models keep the power of 128k-token context in a single GPU midrange.
Highlight points
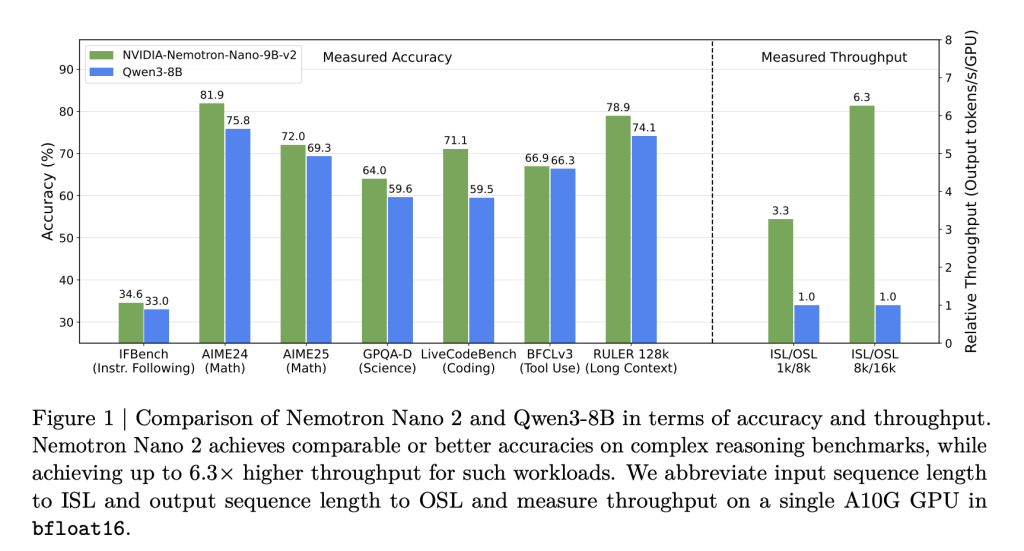
- 6 × through the same model models: Nemotron Nano 2 models bring 6.3 ×'s speed of modeling models such as pass3-8b in display – difficult conditions – without showing accuracy.
- Higher accuracy of the consultation, multilingabilities of multilingualism: Benchmarks showing on-par-par or best results vs models of competition, more than more than peers, code, tools, and Long-Continct.
- Location Length 128k in one GPU: The active construction and active construction of the hybrid makes it possible to use 128,000 tokens in NVIDIA A10G GPU (22GIB).
- Open data and weights: Most datasets including the first, including the code, mathematics, languages, sft, and consultative data, is issued for a fertilizing license.
Hybrid Building: Mbamba meets transformer
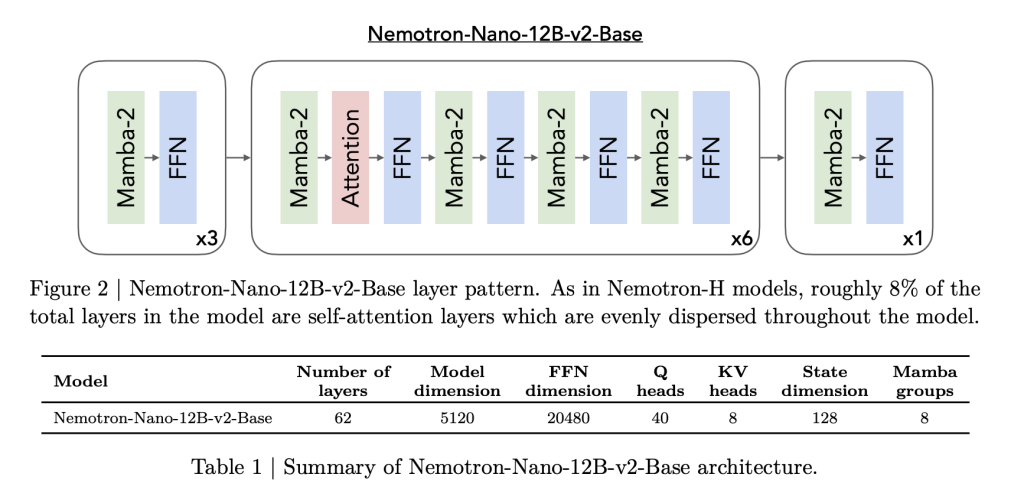
Nemotron Nano 2 is designed in Hybrid Mamba-transformer Backbe, inspired by Nemotron-H formation. Many traditional layers are replaced by the active-2, only 8 percent of the total layers that use attention. This is carefully craved:
- Model details: The 9B-Parameter model has 56 layers (except before 62) the 4480 size, with collected collection and structured state and formatized organizations and for longer maintenance.
- Calls in 2: These fields of the state of the world, which are recently popular as a higher conservative model, combined with several monitoring (saving long reliance), and large feed networks.
This structure empowered the higher obligations in consultation activities that require “reflection” -Long to think of higher entries, where the traditional transformer buildings often slow down.
Training Repeal: Various data variety, open closure
Nemotron Nano 2 models are trained and affected by the 12B teacher parameter model using a broad, high quality corpus. The Nvidia's Overtime Obviously Data is a standby:
- 20t Tokens Pretraining: Data sources include the selected company and web company, statistics, code, code, educational, and stem domains.
- Highlights issued:
- Nemotron-CC-V2: Many Bacterial Languages of B Crawl (15 languages), synthetic, recycling, readiness.
- Nemotron-CC-Math: 133b tokens mathematical content, re-edited in latex, more than 52B “high quality” subset.
- Nemotron-Pretrica code: The source code of the selected gym and quality of quality; A strong and extremely diagnosed.
- Nemotron-Pretetch-SFT: Syntures, the following educational datassets reach the stem, consultation, and common domains.
- Post-Training Data: It includes more than 80b tokens of Good-Tuning (SFT), RLHF, to call the tool, and multilingual details – most open-up datasets to get directly redesigned.
Alignment, Distairation, and Configuration: Opening applicable costs, indicating long-term
The process of oppressing Nvidia model is made up of the Minitron “structures and Mbamba Fromework:
- Information installation Since 12B teachers reduces the model in the 9b parameters, with carrots in the diameter, FFN size, and embedded.
- Multi-Stage SFT and RL: Includes the efficiency of the instruments (BFCL v3), the following (Iveval) performance, DPO and GRPO is reinforced, and the “budgeted budget budgeting).
- NASs directed to memory: With search of properties, specific models are specially designed to model and key-value cache is both ready and residemized A10G GPU status in 108k Memory.
Result: Accessibility speed of 6 × tendency than the competitors are open in cases with large / outgoing tokens, without redeeming the work.
Consideration: High thinking and various skills
In the head test to head, Nematron Nano 2 models 2 Excel models:
| Work / Bench | And Metrono-Nano-9b-V2 | QWEN3-8B | Gemma3-12B |
|---|---|---|---|
| MMK (Normal) | 74.5 | 76.4 | 73.6 |
| MMLU-Pro (5-Shot) | 59.4 | 56.3 | 45.1 |
| GSM8K COT (MATT) | 91.4 | 84.0 | 74.5 |
| Account | 80.5 | 55.4 | 42.4 |
| Humeval + | 58.5 | 57.6 | 36.7 |
| Empire-128k (Long City) | 82.2 | – | 80.7 |
| Global-MMLU-Lite (Avg Multi) | 69.9 | 72.8 | 71.9 |
| MSSM MGIKILINT SANILLE (AVG) | 84.8 | 64.5 | 57.1 |
- Passing (tokens / GPUs) in 8K Outping / 16K output:
- Nemotron-Nano-9B-V2: Upgrading 6.3 × ×3-8B in display tracking.
- Keeps up to 128k-looso with batch size = 1-earlier disadvantaged in Medrange GPus.
Store
The Nemotron Nano 2 Issue 2 is an important moment of vacant LLM research: A possibility of a possible new-operating GPU The construction of the hybrid, the passing of the greater numbers, and higher high datasets set to speed up new items throughout Aicostem AI.
Look Technical information, paper including Models in kissing face. Feel free to look our GITHUB page for tutorials, codes and letters of writing. Also, feel free to follow it Sane and don't forget to join ours 100K + ml subreddit Then sign up for Our newspaper.
Asphazzaq is a Markteach Media Inc. According to a View Business and Developer, Asifi is committed to integrating a good social intelligence. His latest attempt is launched by the launch of the chemistrylife plan for an intelligence, MarktechPost, a devastating intimate practice of a machine learning and deep learning issues that are clearly and easily understood. The platform is adhering to more than two million moon visits, indicating its popularity between the audience.



 to class devices")