gelato-30b-A3B: Base model of GUI Computer-use computer functions, computer models surpass computers like GTA1-32B

How do we teach eI Agents to reliably find and click directly on the screen we say when we give them simple education? A group of researchers from ML Foundations has delivered gelato-30b-A3B, a state of the art model for inputting user complaints designed for computing agents and converting natural language commands into reliable clickable destinations. The model is trained on a 10k Click 100K dataset and achieves an accuracy of 63.88% in Screenspot Pro and 69.15% in OS-World-G, with a refined 74.65%. It surpasses the GTA1-32B and the big vision language models like QWEN3-VL-235B-A22B-Oward.
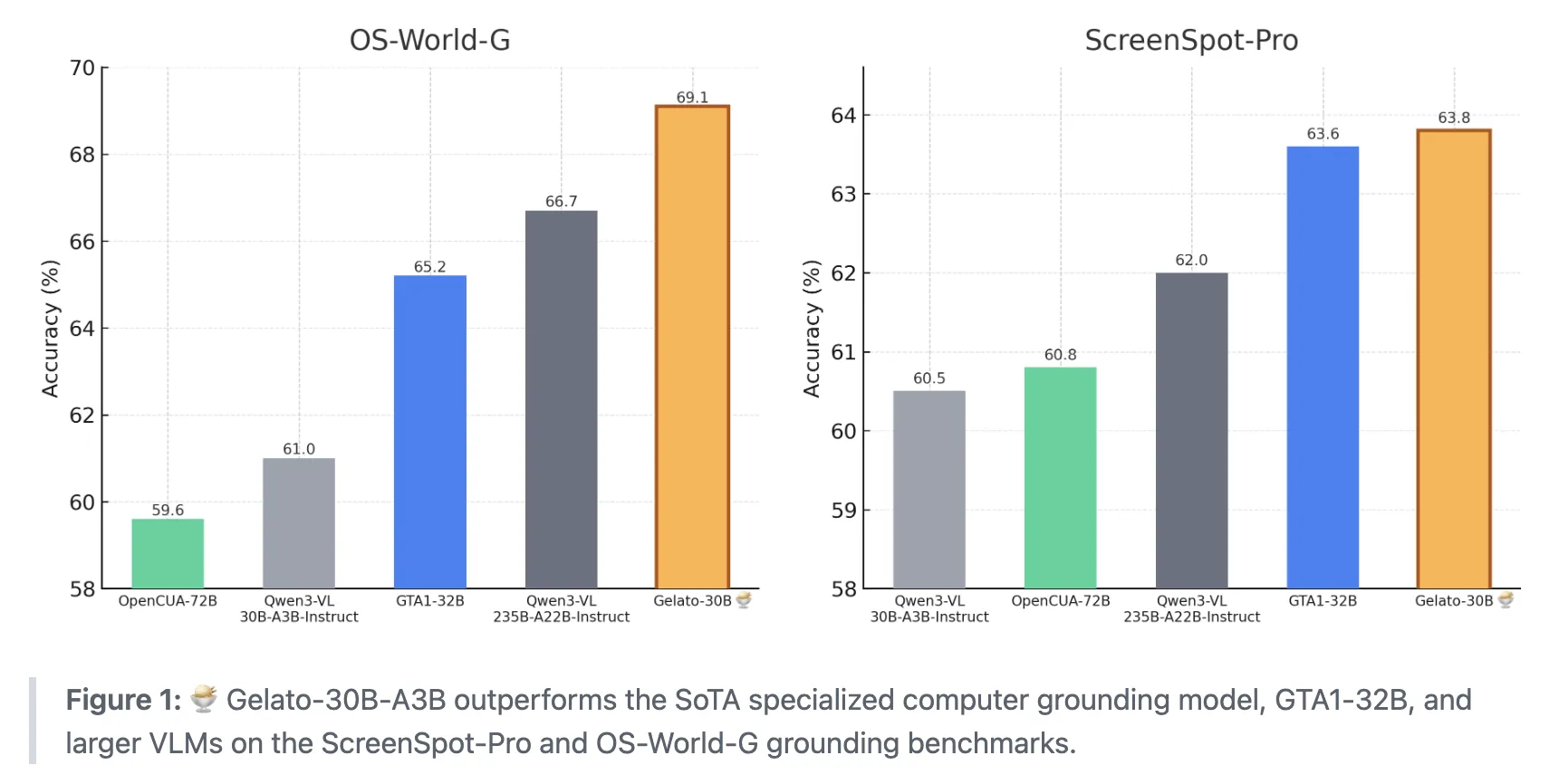
What does gelato 30b A3B stack the agent?
gelato-30b-a3b is a model of 31 parameters of the bar and tunes qwen qwen qwen Qwen3-VL-30B-A3B commands with a combination of professional construction. It takes a screenshot and a text tutorial as input and produces a single link as output.
The model is arranged as part of the base. The programming model, for example GPT 5 in gelato trials, determines the action at the highest level and the gelato calls to solve that object by clicking on the concrete on the screen. This separation between scheduling and deployment is important when an agent must work on multiple applications and applications with different architectures.
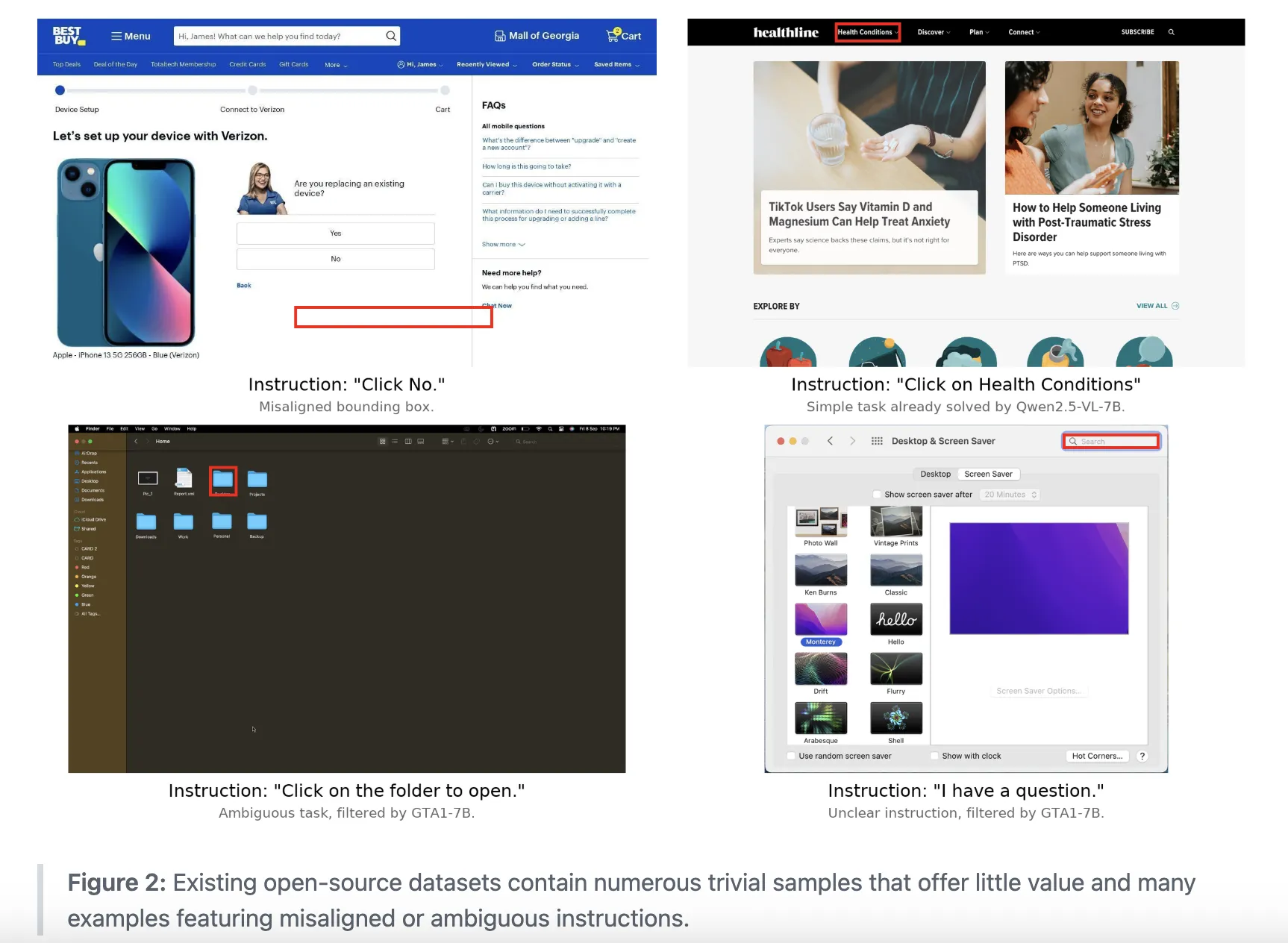
Click 100k, GUI-oriented dataset layer
Click 100k is the lowest data base for gelato. IT Pairs Screen Images with natural language commands, target object binding boxes, symbol sizes, and standard binding boxes. Each sample is set as a lower veil command, for example 'Tap in the area between background options and notification options' for a specific region.
The dataset was created by filtering and combining multiple public sources. The list includes shoveui, autogui, PC Agent e, atlas for atlai, location, pixmo location, Jedi visualization from 85 tutorials from claude-4-sonzo. Each source contributes to a maximum of 50k samples, and all sources are included in a shared schema with images, commands, binding boxes, and standard links.
The research team then ran an aggressive filter pipeline. Omnipaser discards non-real world clicks on visible objects found. Qwen2.5-7b-VL and SE-GUI-3B Remove unlimited examples, such as simple hyperlink clicks. GTA1-7B-2507 and UI-Venus-7b Remove samples from the command and click region. QWEN2.5-7b-VL Baseline trained on a wide 10K Resetset trained that this combination gives a +9 accuracy in Screenspot Pro compared to training on unsampled data.
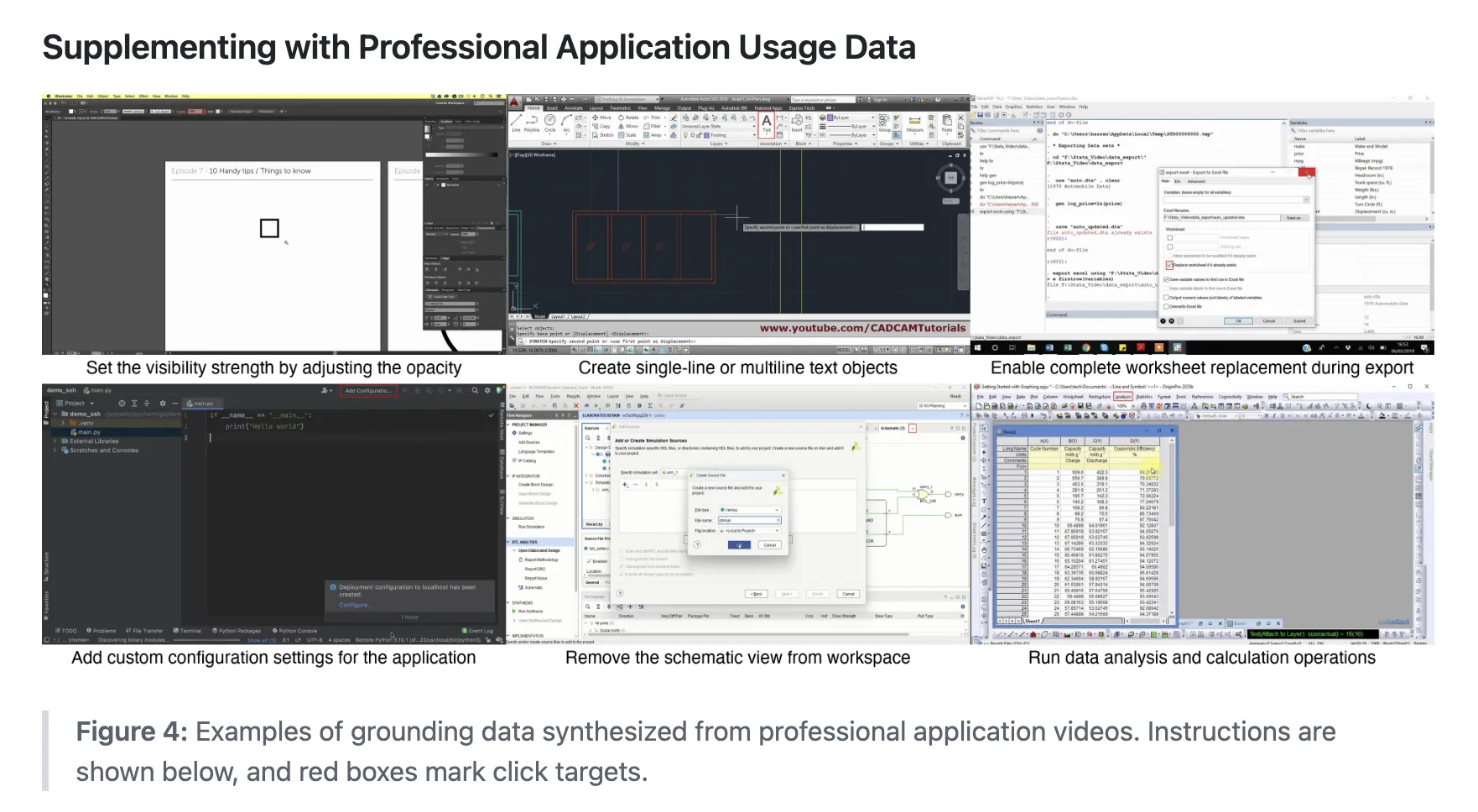
Professional application to cover specific focus. Click 100k add data from UI Vision and jedi subset, and reinforce this with 80+ tutorials for real desktop tools. Claude 4 Sonnet produces binding boxes and video instructions, followed by manual testing and correction.
GRPO training over QWEN3 VL
On the training side, Gelato 30b A3B uses GRPO, a reinforcement learning algorithm found at work in Senseekmath and similar programs. The research group followed the DAPO setup. They remove the KL Divergence term from the target, set the upper limit of the clip at 0.28, and skip rollouts with zero profit. Rewards are starse and only given when the predicted click falls within the target bounding box, similar to the GTA1 recipe.
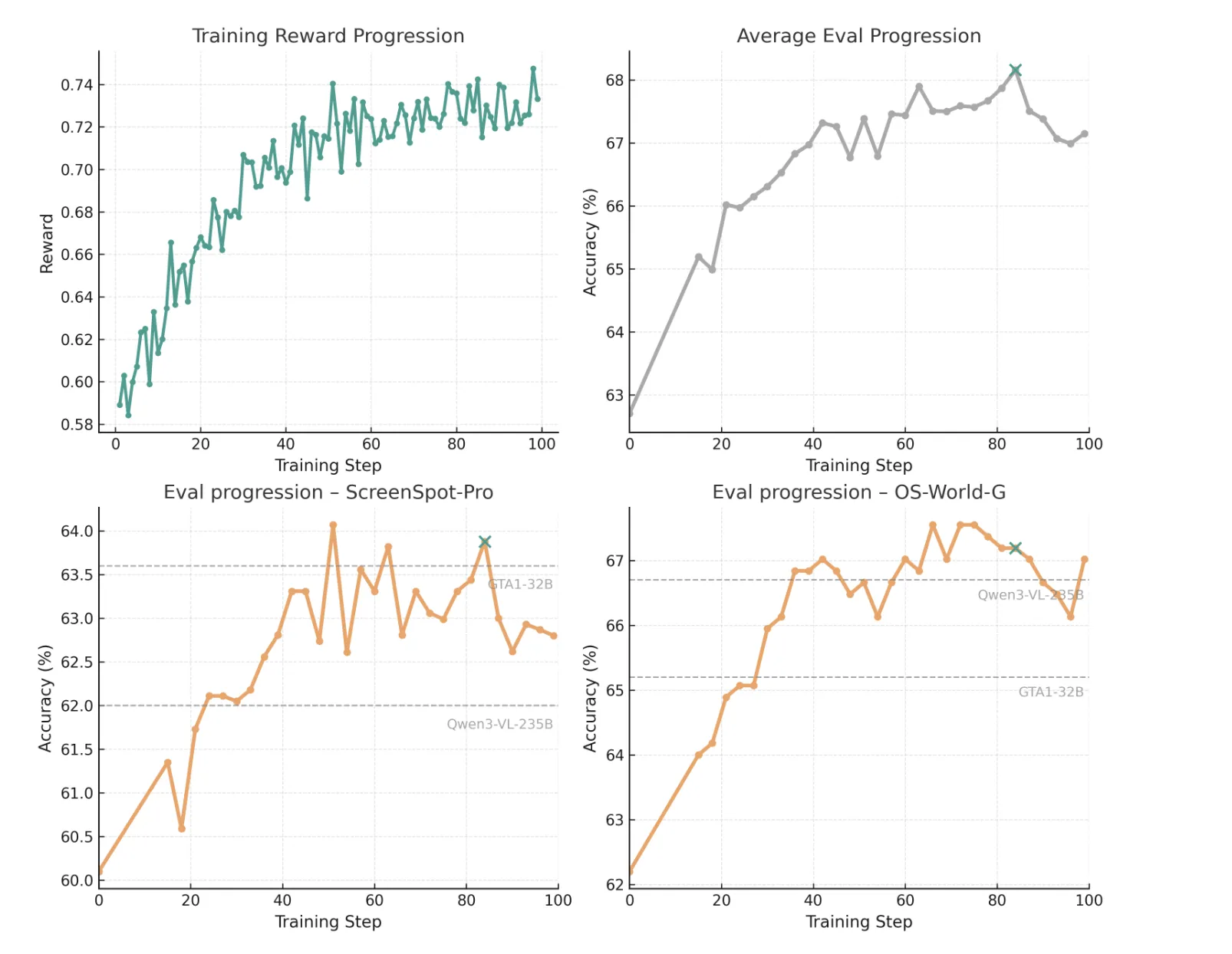
They started from Qwen3 vl 30b A3B command and ran 100 steps of RL on 32 A100 GPU with 40 GB memory. The best CheckPoint comes from stage 84 (marked as a Green Cross in the image above), which is selected for performance which means Screenspot Pro, OS World g, and OS World g refined. This time the model reaches 63.88% in Screenspot-Pro and 67.19% and 73.40% in OS World g and OS World g pure. A simple inhibition strategy, which provides a command to respond with rejection when an object cannot be found, raises the OS-World-G scores to 69.15% and 74.65%.
End to end agent effects in the OS world
To test the gelato gelato above the lower benches, the research team installs it in the GTA1.5 agent system and runs full computer agents in the OS world environment. In this setup GPT 5 works as a planner. Gelato 30b A3B provides placement, the agent has a maximum of 50 steps, and waits 3 seconds between actions.
The study reports that three runs were run on the model with a fixed OS World Snapshot. gelato-30b-A3B achieves an automatic success rate of 58.71% with standard deviation, compared to 56.97% for GTA1 32B in the same harness. Because the OULTIONAL World Test misses other valid solutions, they also use human tests in 20 problem tasks. Under human attack, gelato achieves 61.85% success, while GTA1-32B achieves 59.47%.
Key taken
- gelato-30b-a3b is Qwen3-VL-30B-A3B Blend based Blend based on Art GUI Surchmark rendering in VLCHRMARCRIDS Pro and GTA1-32B and vlms like QWEN3-VL-235B-A22B-Stient.
- The model is trained on 100k clicks, a selected dataset that includes and filters multiple gui shoots and application tracking, pairing real screens with low-level natural language commands and direct connections.
- The gelato-30b-A3B uses the GRPO learning recipe over the Qwen3-VL, with rewards only burning when you click the predictable inside the molded binding box.
- When combined with an agent framework with GPT-5 acting as a Planner, gelato-30B-A3B improves the success rates on OS World Computer in the implementation of GTA1-32B, indicating that better delivery translates into agent completion.
The gelato-30b-a3b is an important step for computer use based on it because it shows that the qwen3-vl model is carefully based on VLSA0-32B and Screens3-A22B-World-g while always being available on the face. Overall, gelato-30b-a3b establishes a clear new foundation for open computing models.
Look It's a waste and Model weight. Feel free to take a look at ours GitHub page for tutorials, code and notebooks. Also, feel free to follow us Kind of stubborn and don't forget to join ours 100K + ML Subreddit and sign up Our newsletter. Wait! Do you telegraph? Now you can join us by telegraph.
AsifAzzaq is the CEO of MarktechPost Media Inc.. as a visionary entrepreneur and developer, Asifi is committed to harnessing the power of social intelligence for good. His latest effort is the launch of a media intelligence platform, MarktechPpost, which stands out for its deep understanding of machine learning and deep learning stories that are technically sound and easily understood by a wide audience. The platform sticks to more than two million monthly views, which shows its popularity among the audience.
Follow Marktechpost: Add us as a favorite source on Google.



